前言
- 本文提出
3D DSN对3d的肝脏数据进行分割,采用完全卷积架构,有效的执行端到端学习和推理,此外条件随机场(CRF)来获得更加精细的分割。 - 通常统计变形模型最流行和成功的分割方法,该方法利用形状先验信息、强度分布以及边界区域信息来描述肝脏的特征和划定界限。但是这些方法过度的依赖人工,或者没有利用3D空间信息,因此如何利用体积上下文信息,提取强大的高级特征来自动分割肝脏一直都为解决。
- 为了充分利用空间信息,提出了
3D CNN,尽管3D CNN没有端到端训练,而且数据有限且存在风险,但依然大量的激励研究者去深入研究3D CNN在医学图像领域的应用。 - 本文采用3D DSN分割,并用条件随机场(CRF)执行轮廓修正,得到最终的结构。
方法
3D DSN的架构如图1所示。 主流网络由11层组成,即6个卷积层,2个max pooling层,2个反卷积层和1个softmax层。 通过第三层和第六层涉及深层监督机制,如灰色虚线框所示。
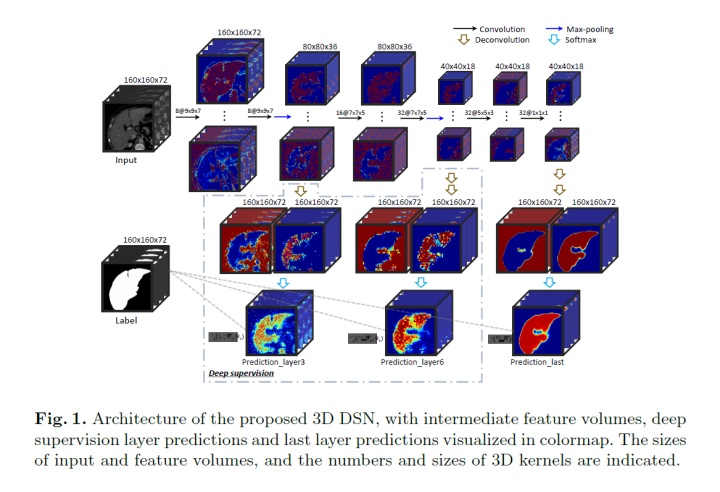
- 为了对体积数据中的空间信息进行充分编码,我们DSN中的所有层都以3D格式构建,如图1所示。3D卷积层和3D
max pooling层交替堆叠来连续提取中间特征。 - 每个卷积层中使用的内核的数量和大小如图1所示。我们设计相对较大的内核大小,以形成适合肝脏识别的接收领域。所有
max pooling层都使用2 * 2 * 2的内核。经过几个阶段的下采样后,特征体积的尺寸逐渐减小,并且比gt_mask的尺寸小得多。在这方面,我们开发3D反卷积层以将这些粗糙feature map桥接到密集概率预测(即变为原来的尺寸大小)。反卷积的时候卷积核大小是333(正向卷积核大小见上图),方向的是尺寸双倍放大。此外反向卷积核在训练的过程中学习得来。
深层监督的学习过程
- 3D网络的学习过程可以认为是提速二分类误差最小化问题,在优化的过程中一个挑战就是:梯度消失,这使得早期层中的损失反向传播无效。这种问题在3D情况下可能更严重,并且不可避免地会降低收敛速度并降低模型的辨别能力。为了应对这一挑战,我们利用注入一些隐藏层的额外监督来抵消梯度消失的不利影响。
- 具体而言,我们使用一些额外的反卷积层来扩展一些低级和中级特征向量。然后使用softmax层来获得用于计算分类误差的
dense预测(监督层的预测)。利用从这些分支预测和最后输出层得到的梯度,可以有效地减轻梯度消失的影响。 - 令wl为l层的权重,W = (w1;w2; …;wL)为主流网络的权重,p (ti | xi;W)表示体素xi属于ti类的概率(
softmax function输出),则最后一个输出层的负对数似然损失如下:
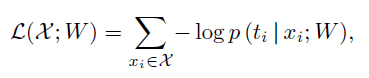
- 其中X表示训练集,从第d层引入深度监督,用Wd =
(w1;w2; …;wd)表示主流网络第d层的权重。使用w^d表示将第d层特征桥接到dense预测(监督层的预测)的权重,深度监督的辅助损失如下:

- 最后,我们采用标准反向传播,通过最小化以下总体目标函数来学习权重W和所有w^d:
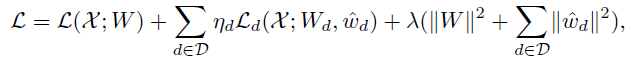
- 其中ηd是ζd的平衡权重,在学习的过程中衰减。D是具有深层监督的所有隐藏层的索引集。 上面公式中第一项对应于最后一层的输出预测, 第二项来自深层监督,提高了网络的识别能力,加快了收敛速度,第三项是权重衰减正则化,λ是权衡超参数。在每次训练迭代中,网络的输入是一个大的体积数据(见图1),并且同时进行来自不同损耗分量的误差反向传播。
使用条件随机场(CRF)进行轮廓修正
- 尽管3D DSN可以生成高质量的概率图,但是如果仅使用阈值概率,则模糊区域的轮廓有时可能是不精确的。 因此,我们进一步采用图形模型来细化分割结果。 考虑到网络已经充分考虑了3D空间信息,我们在横向平面上利用了完全连接的CRF模型,该模型具有高分辨率。 该模型解决了如下能量函数:
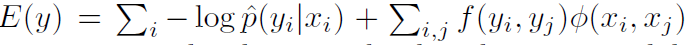
- 第一项是指体素xi被分配标签yi的概率对数, 具体而言,p^(yi|xi)被初始化为来自3D DSN的最后层和分支概率预测的加权平均值,计算公式如下:
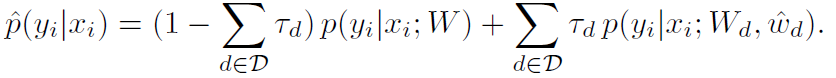
- E(y)中的第二项是
pairwise potential,其中f(yi; yj)=1 if yi != yj and 0 otherwise;∮(xi; xj)通过采用灰度值I和双边位置s来结合局部外观和平滑度,如下:
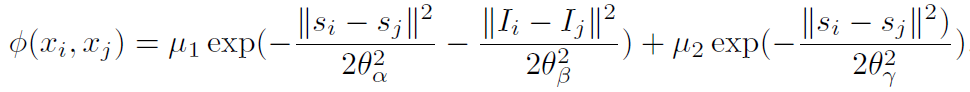
- 使用训练集上的网格搜索来优化一元势中的恒定权重τd和成对势中的参数μ1; μ2; θα; θβ; θγ。
。
实验
- 使用MICCAI-SLiver07 [6]数据集(20组训练和10组测试)。
- 实施细节。我们的3D DSN是通过Theano库实现的。我们从头开始训练网络,权重是从高斯分布(μ= 0;σ= 0:01)初始化的。学习率初始化为0.1,每50个
epochs除以10。深度监督平衡权重初始化为0.3和0.4,每十个epochs衰减5%。