
List、Set与Map
- List 、Set、 Map有什么区别和联系
- list 和set 有共同的父类 它们的用法也是一样的 唯一的不太就是set中不能有相同的元素 list中可以
- list和set的用途非常广泛 list可以完全代替数组来使用
- map 是独立的合集 它使用键值对的方式来储存数据 键不能有重复的 值可以用
- map不像上边两种集合那个用的广泛 不过在servlet 和jsp中 map可是绝对的重中之重 页面之间传值全靠map
List 、Set、 Map都有哪些子类
Collection ├List │├LinkedList │├ArrayList │└Vector │ └Stack └Set |-HashSet └TreeSet Map ├Hashtable ├HashMap └WeakHashMap注意:Map没有继承Collection接口,Map提供key到value的映射。
List
- LinkedList类
- LinkedList实现了List接口,允许null元素。此外LinkedList提供额外的get,remove,insert方法在 LinkedList的首部或尾部。这些操作使LinkedList可被用作堆栈(stack),队列(queue)或双向队列(deque)。
- 注意LinkedList没有同步方法。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List:
List list = Collections.synchronizedList(new LinkedList(...));
特点:寻址困难,插入和删除容易。
ArrayList类
- ArrayList实现了可变大小的数组。它允许所有元素,包括null。ArrayList没有同步。
- size,isEmpty,get,set方法运行时间为常数。但是add方法开销为分摊的常数,添加n个元素需要O(n)的时间。其他的方法运行时间为线性。
- 每个ArrayList实例都有一个容量(Capacity),即用于存储元素的数组的大小。这个容量可随着不断添加新元素而自动增加,但是增长算法并 没有定义。当需要插入大量元素时,在插入前可以调用ensureCapacity方法来增加ArrayList的容量以提高插入效率。
- 和LinkedList一样,ArrayList也是非同步的(unsynchronized)。
- 特点是:寻址容易,插入和删除困难;
Vector类
- Vector非常类似ArrayList,但是Vector是同步的。由Vector创建的Iterator,虽然和ArrayList创建的 Iterator是同一接口,但是,因为Vector是同步的,当一个Iterator被创建而且正在被使用,另一个线程改变了Vector的状态(例 如,添加或删除了一些元素),这时调用Iterator的方法时将抛出ConcurrentModificationException,因此必须捕获该 异常。
Stack 类
- Stack继承自Vector,实现一个后进先出的堆栈。Stack提供5个额外的方法使得 Vector得以被当作堆栈使用。基本的push和pop 方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。Stack刚创建后是空栈。
Set
HashSet类
- 它不允许出现重复元素;
- 不保证集合中元素的顺序
- 允许包含值为null的元素,但最多只能有一个null元素。
- HashSet的实现是不同步的。
TreeSet类
reeSet类实现 Set 接口,该接口由 TreeMap 实例支持。此类保证排序后的 set 按照升序排列元素,根据使用的构造方法不同,可能会按照元素的自然顺序 进行排序,或按照在创建 set 时所提供的比较器进行排序。
- TreeSet描述的是Set的一种变体——可以实现排序等功能的集合,它在讲对象元素添加到集合中时会自动按照某种比较规则将其插入到有序的对象序列中.
HashSet是基于Hash算法实现的,其性能通常优于TreeSet,我们通常都应该使用HashSet,在我们需要排序的功能时,我门才使用TreeSet;
Map接口
Hashtable类
Hashtable继承Map接口,实现一个key-value映射的哈希表。任何非空(non-null)的对象都可作为key或者value。
添加数据使用put(key, value),取出数据使用get(key),这两个基本操作的时间开销为常数。Hashtable 通过initial capacity和load factor两个参数调整性能。通常缺省的load factor 0.75较好地实现了时间和空间的均衡。增大load factor可以节省空间但相应的查找时间将增大,这会影响像get和put这样的操作。
作为key的对象将通过计算其散列函数来确定与之对应的value的位置,因此任何作为key的对象都必须实现hashCode和equals方法。
Hashtable是同步的。
HashMap类
- HashMap和Hashtable类似,不同之处在于HashMap是非同步的,并且允许null,即null value和null key。
其迭代子操作时间开销和HashMap 的容量成比例,因此,不要将HashMap的初始化容量设得过高,或者load factor过低。
- HashMap和Hashtable类似,不同之处在于HashMap是非同步的,并且允许null,即null value和null key。
WeakHashMap类
WeakHashMap是一种改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收。
hashmap遍历的两种方式
HashMap的遍历有两种常用的方法,那就是使用keyset及entryset来进行遍历
方法一:
Map map = new HashMap();
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
}
+ 效率高,以后尽量要使用此种方式!
+ 方法二:
Map map = new HashMap();
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
Object key = iter.next();
Object val = map.get(key);
}
+ 效率低,以后尽量少使用!HashMap的数据结构
HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next.
数据value的值是元素的key的哈希值对数组长度取模得到。如下面第二幅图中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
结构如图所示:
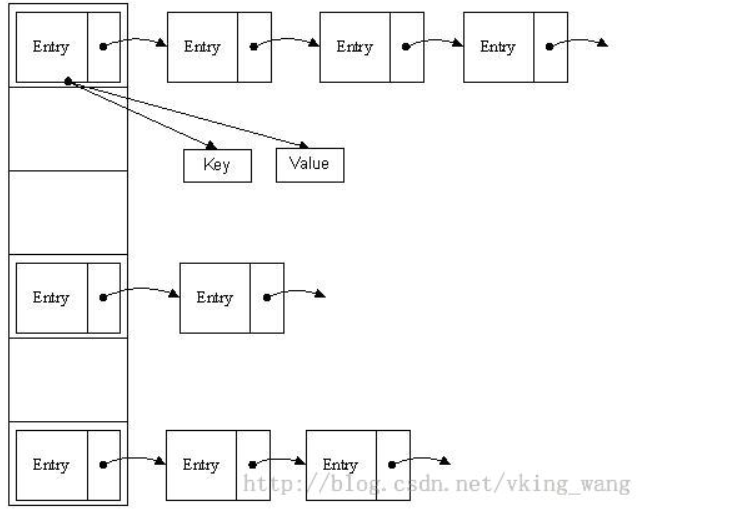
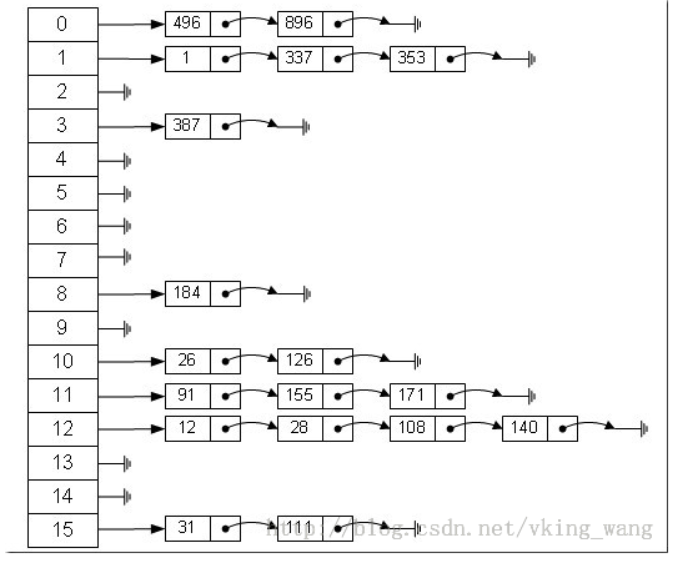
HashMap的存取实现
// 存储时:
int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value; <br/>
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
解决hash冲突的办法
- 开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
再哈希法
链地址法
建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
- 开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
再散列rehash过程
- 当哈希表的容量超过默认容量时,必须调整table的大小。当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一张新表,将原表的映射到新表中。
码字不易,求分享、转发。😄
往期精彩文章