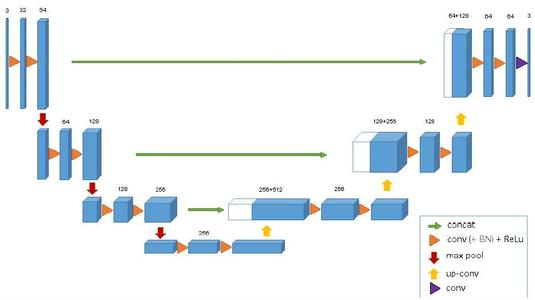
3D Unet
3D卷积代码解释
def conv3d(name, in_layer, ksize, out_channels, padding='SAME', in_channel=0):
- name:每一层的名字
- in_layer:上一层的输出,本层的输入
- ksize:卷积核大小
- padding:卷积方式
W = tf.get_variable(name + 'W', shape=[ksize[0], ksize[1], ksize[2], in_channel, out_channels],
dtype=tf.float32,
initializer=tf.truncated_normal_initializer(0.0, 0.01))
- shape:新变量或现有变量的形状或者维度。大小为3*3*3*in_channel*out_channels
- tf.truncated_normal_initializer:截取的正态分布,均值为0,方差为0.01
- out_channels:输出的维度,in_channel:输入的维度。
- 上面代码是初始化权值w
b = tf.get_variable(
name + 'b', shape=[out_channels], dtype=tf.float32, initializer=tf.constant_initializer(0.1))
- 初始化偏差b
- tf.constant_initializer:常量初始化函数,0.1初始化
- 3D卷积层主要经历了如下几个步骤:
- 初始化过滤器W和偏差b
- 过滤器w对输入数据卷积,之后再dropout(其实dropout就是随机将一些节点置0)
- dropout的输出加上偏差b
- 之后再通过batch_normalization层,最后通过relu函数。
- l2_loss = tf.contrib.layers.l2_regularizer(0.003)(W) 返回一个执行L2正则化的函数,正则项系数为0.003.关于正则化的解释可以参考《统计学习》13页。
- tf.add_to_collection('l2_loss', l2_loss) 将正则化项放到'l2_loss' 列表里面。
- tf.add_to_collection是把多个变量放入一个自己y用引号命名的集合里,也就是把多个变量统一放在一个列表中。
- tf.get_collection与之相反,是从列表中取出所有元素,构成一个新的列表。
3D反卷积代码解释
with tf.name_scope(name + 'op'):
output_shape = tf.stack(
[in_shape[0], in_shape[1] * 2, in_shape[2] * 2, in_shape[3] * 2, out_channels])
deconv = tf.nn.conv3d_transpose(in_layer, W, output_shape, strides=[
1, 2, 2, 2, 1], padding=padding)
bias = tf.nn.relu(tf.nn.bias_add(deconv, b))
- in_shape[1] * 2, in_shape[2] * 2, in_shape[3] * 2 反卷积一次,size要变大两倍。
- out_channels:输出的通道数。每做一次反卷积,通道数减半。
网络结构
- placeholder,占位符,在tensorflow中类似于函数参数,运行时必须传入值。
conv1_1 = conv3d('conv1_1', X, [3, 3, 3],
root_layers, padding="SAME") # batch_size*512*512*64
conv1_2 = conv3d('conv1_2', conv1_1, [
3, 3, 3], root_layers, padding='SAME') # 融合层1 512*512*64
- 512*512是数据块的大小,有一维数据块大小没写出来。64是通道数。root_layers=64
flat_labels = tf.reshape(tf.one_hot(Y, CLASSES), [-1, CLASSES])
- 简单解释一下什么是one_hot,one-hot code也称独热码,通常用于分类任务中作为最后的FC层的输出。在机器学习中对于离散型的分类型的数据,需要对其进行数字化,比如说对性别这一属性,只有男女两种值,用数字化表达,指定男性为0,女性为1,那么一个特征向量(1,0,1),转换成独热码(one_hot)就变成([1,0],[0,1],[1,0])。
loss_map = tf.nn.softmax_cross_entropy_with_logits(
logits=flat_logits, labels=flat_labels)
解释在下面的图片:

损失函数
w = tf.reduce_mean(Y)
W[0] = w
W[1] = 1-w
class_weights = W
weight_map = tf.multiply(flat_labels, class_weights)
weight_maps = tf.reduce_sum(weight_map, axis=1)
weighted_loss = tf.multiply(loss_map + loss1 + loss2, weight_maps)
- 做图像分割的时候,loss是所有点交叉熵求和,这样所有的点权重都是一样的,这样很不合理,因为不可能图像的前景和背景一样大,如果一张图像就10个像素是前景,如果1:1权重训练的时候很容易被忽略
- 所以增加点交叉熵的权重项可以让训练的时候都关注一下这些前景很小的点。
- classweight就是统计金标准中正负样本比例算的,比如 10个正样本 100个负样本,那就给正样本10倍权重
- flat_labels 是金标准转换成one_hot码之后的结果,如果是前景点值为[1,0],背景点值为[0,1]. 而class_weights[0]是正样本比值,class_weights[1]是负样本比值,所以weight_map = tf.multiply(flat_labels, class_weights) 是由金标准计算出来的权重map。
- tf.multiply(loss_map + loss1 + loss2, weight_maps) ,计算loss的时候加入了DSN机制,可以加速收敛。
#计算模型准确度
pre_img = tf.argmax(pre, -1) #返回最大的那个数值所在的下标。
ans = tf.equal(pre_img, Y) #tf.equal(A, B)是对比这两个矩阵或者向量的相等的元素,如果是相等的那就返回True,反正返回False,返回的值的矩阵维度和A是一样的
acc = tf.reduce_mean(tf.cast(ans, tf.float32)) #tf.cast(ans, tf.float32) 原来x的数据格式是bool, 那么将其转化成float以后,就能够将其转化成0和1的序列。
- 这个函数的计算公式为:rates = tf.train.exponential_decay(learning_rate, global_, decay_steps, decay_rate, staircase=True)
- decayed_learning_rate=learining_rate*decay_rate^(global_step/decay_steps)
- 其中,rates为每一轮优化时使用的学习率;
- learning_rate为事先设定的初始学习率;
- decay_rate为衰减系数;
- decay_steps为衰减速度。
- 而tf.train.exponential_decay函数则可以通过staircase(默认值为False,当为True时,(global_step/decay_steps)则被转化为整数) ,选择不同的衰减方式。
数据读取
- 改成了DSN的那个数据读取方式,Data_Generator.py