1、摘要
- 研究条件对抗网络作为图像到图像转换问题的通用解决方案。网络不仅学习从输入图像到输出图像的映射,还学习了用于训练该映射的损失函数。这使得可以用相同的方法解决传统上需要不同损失函数的问题。这项工作表明我们可以在不用手动设计损失函数的情况下获得合理的结果。
2、介绍
- 我们将图像到图像的转换定义为一个场景到另一个场景的转换,如图一的
input与output所示,在传统上,每一个转换任务都需要单独训练一个机器模型,尽管这些模型的最终目的都是一样的:从像素预测像素。而本文的目标是为所有这些像素转换问题开发一个通用框架。

- 卷积神经网络(CNNs)成为各种图像预测问题背后的共同主力。 但仍需要进行大量的手工操作来设计有效的损失函数。 使用CNN针对不同的问题,需要手动设计不同的损失函数,例如,输出清晰,逼真的图像…..这是一个开放的问题,通常需要各种不同的专业知识。
- 如果我们只能指定一个高级目标,然后自动学习适合于这一目标的损失函数,那将是非常可取的。这也就是生成性对抗网络(GAN)所做的事情。GAN可以自动学习损失函数去区分输出图像时真实的还是伪造的,所以它可以应用于传统上需要非常多不同类型的损失函数的大量任务。
- 本文的主要贡献是证明在有各种各样的问题上,
conditional GANs produce reasonable results.我们的第二个贡献是提供一个足以取得良好结果的简单框架,并分析几个重要架构选择的影响。 - 图像条件模型已经从法线贴图[54],未来帧预测[39],产品照片生成[58]以及稀疏注释[30,47]的图像生成中解决了图像预测问题。
- 我们的框架不同之处在于没有任何特定应用程序。这使我们的设置比大多数其他设置简单得多。在生成器(
generator)和判别器(discriminator)几个架构的选择中,生成器基于U-net网络,判别器选择卷积PatchGAN分类器,仅在图像块的比例下惩罚结构。
3、方法
- GANs是生成模型,可以学习从随机噪声向量z到输出图像y,
G : z -> y。相反,条件GANs学习从观察图像x和随机噪声向量z到y的映射,G : {x; z} -> y.对生成器G进行训练以产生输出,使这个输出与对抗训练过的判别器产生的“真实”图像无法区分,D,经过训练,尽可能地检测生成器的“fakes”。 训练过程如图二所示:
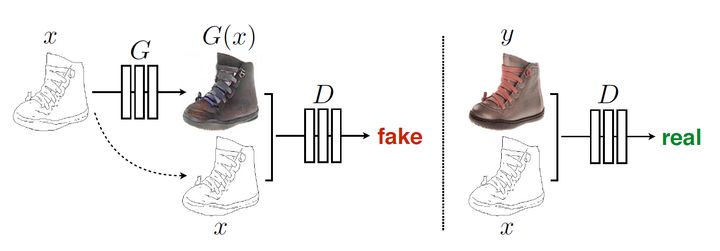
3.1 目标
conditional GAN的目标方程可以表示为:
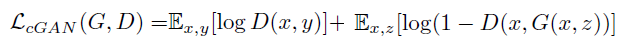
- 其中G试图最小化这个目标,而D试图最大化目标形成对抗。
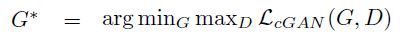
- 为了测试
discriminator的重要性,我们还比较了一个无条件变量,其中discriminator没有观察量x,公式如下:
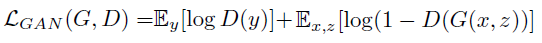
- 以前的方法发现将
GAN objective与更多传统的loss混合是有益的,例如L2距离。discriminator的工作保持不变,但是generator的任务不仅是fool the discriminator,而且还要接近L2意义上的ground truth output。 我们还探索了这个选项,使用L1距离而不是L2,因为L1鼓励减少模糊:
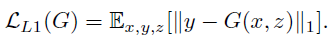
- 最终我们的目标函数变成:
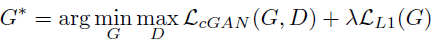
- 如果没有随机噪声向量z,网络仍然可以学习从x到y的映射,但会产生确定性输出,因此无法匹配
delta函数以外的任何分布。 过去的条件GAN已经意识到了这一点并且除了x之外还提供了高斯噪声z作为generator的输入。 - 对于我们的最终模型,我们仅以
dropout的形式提供噪声,在训练和测试的时候应用我们generator的多个层,尽管存在dropout噪音,但我们观察到网络输出中只有轻微的随机性。 设计产生高随机输出的条件GAN,从而捕获它们建模的条件分布的完整熵,是当前工作留下的一个重要问题。
3.2 网络结构
- 网络结构在论文Unsupervised representation
learning with deep convolutional generative adversarial
networks的网络结构的基础上微调。generator和discriminator采用的都是convolution-BatchNorm-ReLu的形式。包含了下面主要讨论的功能。3.2.1 Generator with skips
- 要求输入与输出大致对齐,
shape大小一样,基于这个考虑设计generator的架构,为了给generator提供一种信息瓶颈的方法,按照U-net的方式进行跳转连接。U-net原理可参考论文笔记:Unet用于医学图像分割的卷积网络
3.2.2 马尔可夫鉴别器(PatchGAN)
- 众所周知,L2损失在图像生成问题上产生模糊结果,见图4。 虽然这些损失不能鼓励高频脆度,但在许多情况下它们仍能准确地捕获低频。 对于这种情况的问题,我们不需要一个全新的框架来强制低频率的正确性。 L1已经做好了。

- 这促使限制GAN鉴别器仅模拟高频结构,依赖于L1项来强制低频正确性(方程4)。为了模拟高频,将我们的注意力限制在局部图像块中的结构就足够了。因此,我们设计了一个鉴别器结构,我们将其称为PatchGAN,它只对补丁规模的结构进行惩罚。该鉴别器试图鉴别图像中的每个N*N贴片是真实的还是假的。我们在图像中对这个鉴别器进行了卷积处理,平均所有响应以提供D的最终输出。
- N可以比图像的完整尺寸小得多,并且仍然可以产生高质量的结果。这是有利的,因为较小的PatchGAN具有较少的参数,运行得更快,并且可以应用于任意大的图像。这种鉴别器有效地将图像建模为马尔可夫随机场.
3.3 Optimization and inference
- 为了优化网络,遵循论文Generative Adversarial Nets
中的标准方法:我们固定D的参数然后在G上交替执行梯度下降。如原始GAN论文中提到的一样,我们不是最小化
log(1-D(x;G(x; z))而是最大化logD(x;G(x; z))。我们使用minibatch SGD并应用Adam优化器,学习率设为0:0002,动量参数β1 = 0.5, β2 = 0.999. - 在预测时,我们以与训练阶段完全相同的方式运行
generator。 这与通常的协议不同之处在于我们在测试时应用了dropout,并且我们在test batch上应用了batch normalization,而不是训练批次的汇总统计数据。 当批量大小设置为1时,这种batch normalization的方法被称为instance normalization。 并且已被证明在图像生成任务中有效[53]。 在我们的实验中,我们根据实验使用1到10之间的批量大小。
4、Experiments
- 实验部分主要讲用了哪些数据集,做了哪些对比试验,结果分析以及一些评估标准。就不一一详细写出来了。
5、总结
- 总的来说,我个人觉得这篇文章的只是给
Generative Adversarial Nets多找了几个应用场景,为图像到图像的转换的转换提供了一个通用的框架,局部像素处理,平均所有块响应以提供D的最终输出以及平均所有响应以提供D的最终输出。是个很好的创新点。 - 此外看这篇文章之前需要GAN网络的基础。可以先看一下论文Generative Adversarial Nets ,或者先看一下李宏毅教授讲解GAN网络的视频。我记得是在他的机器学习课程的第18节,在微信公众号:轮子工厂 后台回复:机器学习,可获取李宏毅教授整套机器学习视频。