软件
- matlab2018a(2015版本以上最好,有的函数旧版本不兼容), vlfeat-0.9.18
源码结构
0globalset
0globalset/makeGlobalConst.m:记录程序要用到的全部目录路径、参数设置,点击运行,参数就会更新,并保存到const.mat中。一般只需要根据自己的本机情况修改根目录路径:
%% 根目录
FP_WORK = 'E:\文献\2DNAF\';
0globalset/addConstpath.m:把文件夹内的全部路径加入到环境变量(否则有的跨文件夹函数就找不到)。
NAF
NAFmain.m是程序运行的入口,参见代码的注释可以知道采用NAF的方法分割具体需要哪些步骤。- 数据预处理(preprocess.m):
- 首先将训练数据的img和label都存到
train.mat中,变量名为:trainimgdata。并存在2DNAF\database\oridata\oritrain文件夹中。 - 之后再按照步长宽和步长分别为NPX、NPX、NIX、NIY对数据进行切分,切分成重叠的像素块,因为重叠是核心的方法,如果不重叠,就没有容错率,KNN判出来是什么就必须是什么,如下图:
- 首先将训练数据的img和label都存到

比如这个,如果没有重叠,会少标记3个像素,多标记1个像素;如果重叠,哪怕每个块像素都有漏分或者多分,也能产生一个投票数目,通过设定一个阈值就能更平滑地去分割。
比如阈值设为2,也就是被2次判定为目标像素的才真的判定为目标像素,这样的话就是完美的分割;阈值设为1,只是多标记了2个像素而已。
对img和label分块好的数据存放在
trainpatches.mat中,和train.mat放在同一个文件夹中,trainpatches.mat包含如下信息:patches(patchidx).imgpatch = imgpatch;%灰度图像快
patches(patchidx).gtpatch = gtpatch;%label图像快
patches(patchidx).fileidx = fileidx;%所属的图像文件ID
patches(patchidx).mx = mx;%相对左上坐标X
patches(patchidx).my = my;%相对左上坐标Y
patches(patchidx).ctrx = ceil(mx+px/2 -1);%相对中心X坐标
patches(patchidx).ctry = ceil(my+py/2 -1);%相对中心Y坐标
patches(patchidx).gtcl = culgtcl(gtpatch,1);%对应存入的标签,返回像素为1的像素值个数占总像素个数的比例
patches(patchidx).pid = patchidx;%PID
之后再按照像素为1的像素值个数占总像素个数的比例(gtcl)将块数据分成11类,只要是因为数据太多,内存装载不下,所以需要分11次处理,视情况而定,可以多分一些类,名字为
i_trainpatches.mat.makeFeaPos.m:外部特征提取,采邻域样本特征值。FW为邻域的宽度,要大于块的长度。生成的随机领域坐标存在database\feature_aux\NAFfpos.mat中。NAFtrain():训练NAF。
extNAFFeature:训练之前需要先提取块(patches)的特征向量,先像素归一化,然后提取均值 / 标准差 / 最小值 / 最大值 / 中位数 / 中心3×3的纹理特征(LBP) / 邻域特征。提取向量特征的时候是提取上一步分好成11类中每一类的特征,并保存在i_trainFea.mat中。- 之后再将已经分成11类的
i_trainpatches.mat中的label矩阵存储方式变成向量,方便计算,存储在\feature_aux\gtmat.mat中。 - 随机选择特征值,即随机选择
i_trainFea.mat中的值,保存在features变量中(第一列是pid,第2-7是那些均值之类的特征,剩下的都是邻域特征),然后计算pairdist距离,因为KNN是根据距离来找到最相似的图像的。距离公式和过程如下:


L0 范数,含义为矩阵含0 的个数,分数下侧为块像素的大小。pairdist 的值越大,说明两个块像素的GT 图像差异越大,块像素越不相似;反之,如果pairdist 的值越小,则说明两个块像素的GT 图像值几乎相同,块像素相似程度越高。
将pairdist距离和随机选择的特征传到构造树的函数中就可以训练树了。
makeNAFtree.m构建树:- 随机取阈值t,按照特征值得大小将块的特征分成左右两个子树,训练树,通过学习获得阈值t使得熵Eq取得最大值,Eq的计算公式如下:

- 其中,Nleft、Nright 分别左侧和右侧的儿子节点, AvgDist 表示在节点Ni 处内部的块像素聚集程度。块像素越聚集,AvgDist 应该越小,块像素越分散,AvgDist 应该越大,所以定义AvgDist 为“距离”的平均值:

- 找到使得熵Ep取得最大值的特征和阈值,就近似地将距离接近的块像素分到了一堆去。
测试
- 同样需要先将测试数据分块,再分成11类,然后提取均值 / 标准差 / 最小值 / 最大值 / 中位数 / 中心3×3的纹理特征(LBP) / 邻域特征等特征,保存在
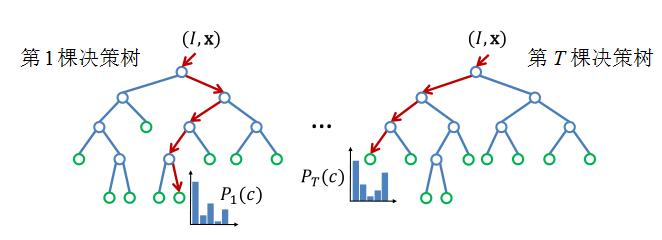
testFea.mat中。 - 再将测试数据的特征传入之前训练好的树,再将每个块像素遍历INARF,每棵INAT都会得到它的KNN 训练块像素编号,把这些编号进行计数后由大到小排序,前KNN_K 个块像素就是被多棵INAT 都判定为相似的最相似训练块像素。如图4-7 所示为一个红色块像素PA 遍历INARF 的3 棵树的过程。第一棵树INAT1测试了N1 处的特征后,认为应该分到N3,再在N3 处测试特征后,认为应该分到N4,N4 是叶子节点,存储着“1,3,5,6”,它们都是具有和PA 相似特征的块像素。INAT2 在N3 处给出了“3,5,7,9”的结果,INAT3 在N5 处给出了“3,5,9,10”的结果,最后通过统计,输入块像素被三棵树判定为和“3”、“5”相似,被两棵树判定为和“9”相似,其余都仅被一棵树认为相似,如果KNN_K取4,那么最相似的四个块像素可能为“3,5,9,1”,
- “可能”的意思是,“1”、“6”、“7”、“10”都可能被选为第四相似的块像素。在这里不能仅仅根据这个统计数字来对最终相似块像素做一个判断,比如“3”、“5”块像素都被三棵树认为相似,只是因为排序算法的特性巧合地让“3”排到了“5”前面,它们的相似程度都是相同的。增加树的数目可以让被选中次数更加有辨别力,但是会增加训练和测试的复杂程度,并且总可能会发生被选中次数相同的情况。

- 为了解决这个问题,INARF 的测试采用协相关系数来比较当前测试块像素和KNN 训练块像素之间的相似程度。协相关系数(correlation coefficient, CC),计算公式如下:

- 其中,mean 表示取均值,PA、PB 的尺寸都是L×W 的。注意分母不能为0,就要求PA、PB 的都不能是像素值全相同的矩阵,因此一旦检测到块像素的值全相同,则随机在模板上的一个位置增加0.0001。如果PA、PB 非常相似,那么CC 会趋近于1;如果PA、PB 反色非常相似,则CC 会趋近于-1;而如果PA、PB 不相似,CC 会趋近于0。只要找出“3,5,9,1”中和测试块像素计算CC 后绝对值最大的一个训练块像素,就是最相似块像素。再将这个最相似块像素的GT 图像作为测试块像素的GT 图像,作为分类结果。