基于形状的人体检测和通过分层部分模板进行分段匹配
1.介绍
1.1 Previous Work
形状建模或形状特征提取方案可以大致分为两类。
- 基于全局和密集的特征提取方法,人被模拟成全局模板。需要大量的训练集。
- 基于稀疏局部特征,或者部分视觉集合表示物体形状的方法(基于可变部分模型方法)。处理部分遮挡的物体特别有效。检测器分别针对每个身体部位进行训练,并与二级分类器组合。问题是在非常混乱的图像中,可能产生太多的检测假设,因此需要鲁棒的组合方法来组合这些检测。
基于可变部分模型方法法已经成功的运用到很多的视觉处理当中。
基于全局的方法训练数据集单一,分类功能强大,它们比基于可变部分模型的方法简单很多。
在基于可变部分模型方法中,每个部分都需要分开训练,此外还必须训练一个额外的装配分类器。相对于基于全局的方法,它更容易处理部分遮挡的图像,而且也更加灵活。
基于部分模型还可以结合形状外观线索,外观线索结合运动线索,同时检测和分割。
一些检测方法构建了基于树的数据结构来进行有效的形状匹配,每个窗口基于模板匹配和最邻近搜索来计算得分。
在监控的场景,运动斑点信息为人类检测提供了非常可靠的线索。这些基于斑点的方法在计算上比纯粹的基于形状的方法更高效。但是他俩的共同问题是结果取决于背景减法或者运动分割的情况。
我们的方法提出的动机如下:
- 分层模板匹配是一种便捷的方法去有效地整合形状的检测和分割,但由于需要收集和匹配大量全局形状模型导致计算量大。
- 之前的大多数识别方法主要是在大量的人类中心对齐的二值样本上训练分类器,然而由于图像中人体高度铰接且姿势不一,这就需要大量的对齐了的训练样本,而且还有可能使结果偏向训练样本。也就是说训练之后的分类器泛化能力会受到影响。
- 可变形零件模型和多个基于实例的学习方案对本地化对象分割非常有效,但受精度和姿势约束。
1.2 Overview of Our Approach(方法概述)
- 在本文中,我们解决了同时检测和分割多个人类(可能部分被遮挡)的困难。为了实现这一目标,提出了一种结合可视化学习(discriminative learning)的分层部分模型匹配方法来建立一个通用的人类检测器。
- 给定输入图像,该检测器返回人类边框作为精准的分割。
- 我们的方法优于基于局部和基于全局的方法。人类检测器是通过分解全局模型构建一个更加灵活和有效的部分模板树人体模型,它能更有效的匹配人体姿势。然后估计的姿势通过合成部件自动检测。
- 使用分层部分模板匹配方案时,为了更好的区分人和非人类,我们提出一种姿态自适应特征提取方法。它能更好的处理局部形状空间重复的事件。
- 我们在人体的正面和反面样本上面分割人体姿势,并在姿势局部邻域进行特征自适应提取。再将所有可能的姿势实例集合映射到规范的姿势上,即任意姿势上的点要与规范姿势一一对应,
- 将树的匹配算法用于处理多个封闭的人体,检测假设集由通用的人体检测器产生,然后通过基于形状匹配分数重新评估和精细遮挡分析的迭代过程来改进和优化。
- 我们的主要贡献总结如下:
- 介绍部分模板树模型和自动学习算法,并应用于人体检测和姿势分割。将流行的基于局部零件的物体检测器与基于全局形状模板的方案相结合。
- 提出快速封层部分模板匹配算法根据局部图像的线索来估计人体的形状和姿势,人的形状和姿势由部分参数模型表示。
- 在任意姿势和规范姿势的轮廓点组之间建立一对一的对应关系。
- 树匹配算法也被扩展到具有挑战性的监控场景中处理多次闭塞的人类检测和分割,我们通过基于形状匹配分数重新评估和精细遮挡分析的迭代过程以贪婪方式执行优化来估计人体配置。
- 第2节介绍了我们的分层部分模板匹配方法的细节。
- 第3节描述了用于学习泛型的姿态适应特征提取方法人体探测器。
- 第4节扩展了到个人类检测和细分的方法。
- 第5节简要介绍了框架中运动和几何线索的结合。
- 第6节介绍实验和评估。
2 HIERARCHICAL PART-TEMPLATE MATCHING
- 引入了一种分层形状匹配方法,以有效地搜索粗糙的人类姿势(形状),并计算每个候选窗口检测的匹配分数,为了实现这一点,我们通过利用基于局部组件和全局形状模板的方法将它们结合在统一的自顶向下和自下而上的搜索方案中, 具体来说,我们通过将全局形状模型分解为零件,并构建一个新的基于部件模板的树,从人物形状的训练数据库中获取部件模型之间的外观联系。
2.1 Generating the Part-Template Tree Model(生成部分模板树模型)
- 由于真实图像中人体姿态自由度高,直接从真实的图像中构建形状模型需要大量的真实轮廓数据集,这给训练样本对齐带来了很大的困难,所以我们使用简单的姿势生成器通过零件合成生成一组灵活的全局形状模型,然后使用身体部分分解构建零件模板层次结构。平行四边形部分在空间上组合,用于模拟粗糙的人类部分形状。 我们通过在空间上分解全局形状模型来获得部分模板模型,并构建一个部分模板树来捕获人类姿态变化。 之后,我们再通过从一小组真实姿态图像学习来优化合成树模型。
2.1.1 Synthesizing Global Shape Models(合成全局形状模型)
- 为捕捉人体姿态,用6个区域:头、躯干、两只手和两条腿来表示人体。通过在空间中合成这些区域形成全局形状模型。每个部分区域的形状由水平平行四边形建模,其特征位于其中心位置(2 dofs),大小(2 dofs)和方向参数(1 dof)。 因此,全身的自由度系数是5*6=30.(dofs:自由度)。
- 我们生成这些全局模型主要是为了通过空间分解获得自动姿势对齐紧凑的部分模板模型集。给予躯干位置作为参考,其余参数被视为在在线检测/测试阶段估计的隐藏变量。
- 全局形状的6个自由度(头、躯干、两只手和两条腿)即6个参数在其范围内的取值为{3; 2; 3; 3; 3; 3}(每个自由度可以对应有几个姿势),也就是说部分实例可以独立组合成32333*3=486种全局模型形状。
2.1.2 Generating Parts by Decomposition(通过分解生产零件)
- 全局形状模型的数量由每个部分区域(合成之前)的自由度确定,部分模板的数量等于树中的节点数,所以它远小于全局模型。
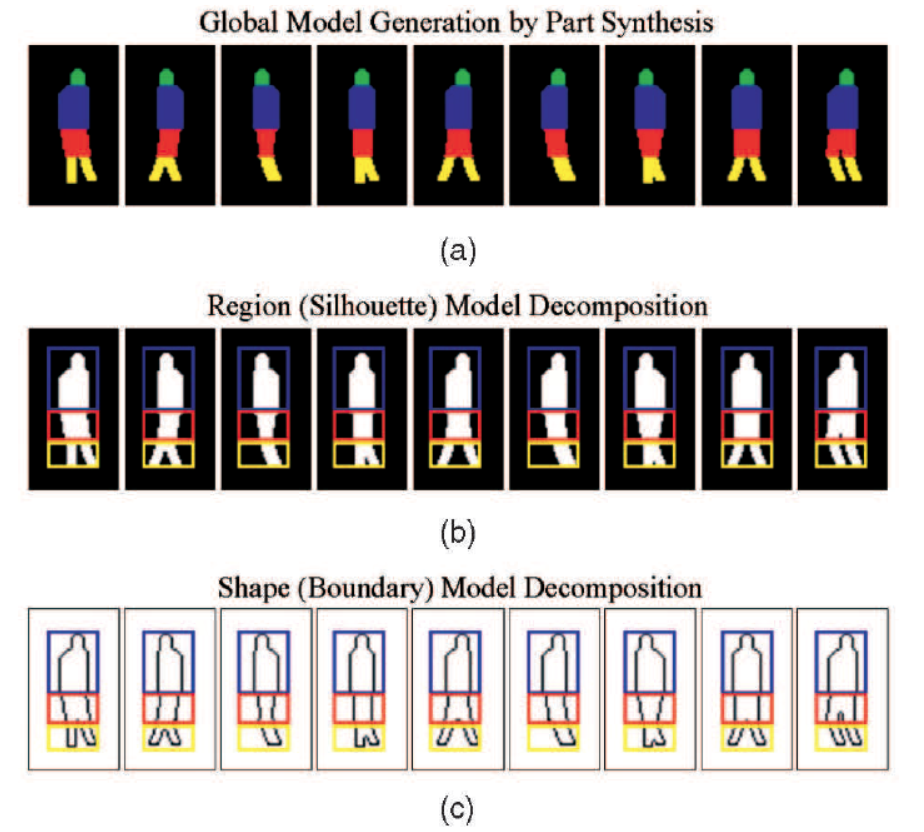
- 先将全局模型分成3各部分(头躯体(ht),大腿(ul)和小腿部(11)),如图所示。
2.1.3 Constructing an Initial Tree Model Using Parts(使用零件构建初始树模型)
- 给定索引部分的集合,通过将分解的部分区域和边界片段放置在树中来构建部分模板树,如图所示。树边缘(或链接)是根据全局形状模型中部分索引之间的关系自动确定的。
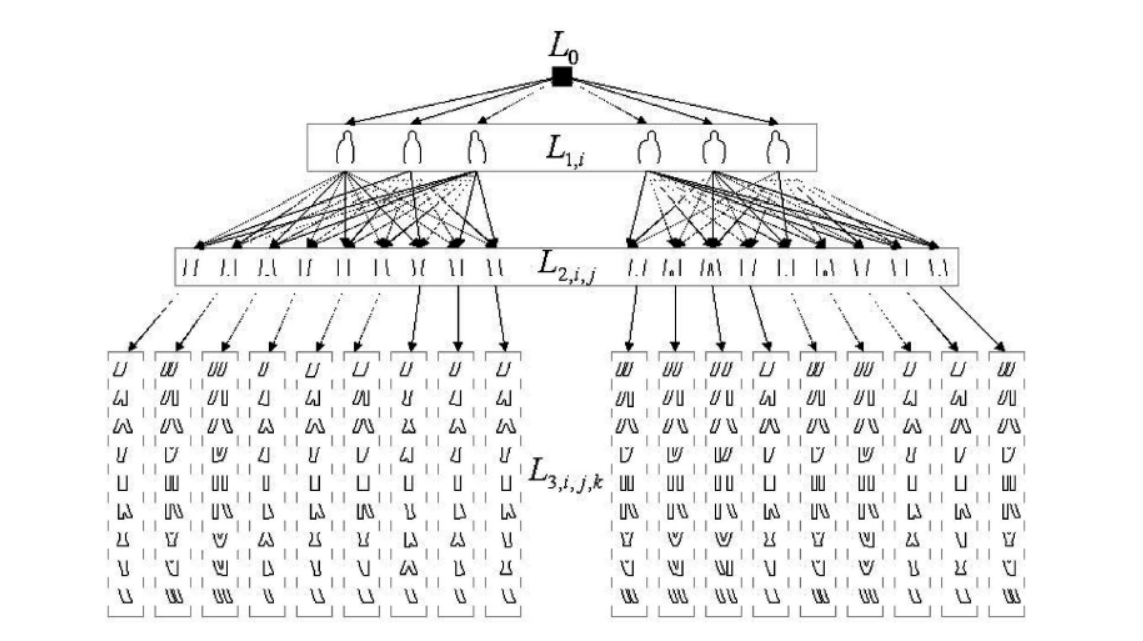
- 树中的每个部分模板表示零件的一个实例,也可以被视为参数模型,其中零件位置和尺寸是模型参数。
- 树中的部分模板的数量直接由生成的全局形状模型的数量决定。在生成全局形状模型时,通过更精细的离散化和更广泛的参数范围可以获得更大的一部分模板。但是通过参考树中的模板数量,虽然计算需求的线性增加,但匹配成本几乎不变。速度非常快。
- 初始树结构和部分模板由上述合成剪影构建,但是通过从实际图像学习来进行细化,这在下面的部分描述。在上图中,任何树路径(从根节点到叶节点)唯一地确定全局形状模型,并且唯一树路径与任何全局形状模型相关联。
2.2 Learning the Part-Template Tree(学习部分模板树 )
- 所有全局形状模型的集合通过枚举所有可能的部分参数形成,因此构造的部分模板树不包含来自真实人类剪影的任何先前统计。所以,我们通过将它们与真正的人物剪影相匹配来学习部分模板的出现概率。由于我们将零件模板模型放置在树形配置中,所以先验值被估计为条件概率分布(每个内部树节点处的分支概率)。
- 为了通过将树匹配到输入图像来更有效和可靠地估计人的形状和姿势,我们使用真实图像来学习与部分模板树模型的边缘相关联的概率。具体地,通过将树匹配到一组人体剪影图像来执行学习。目标是明确地估计分支概率分布,即在每个树层中的树边缘(图2中连接两个连续层之间的节点的箭头)的条件分布,以处理观察到的形状关节的范围。例如,给定层L0处的空节点,我们基于其在训练轮廓集中的发生频率来估计层L1处的六个ht模型的概率分布。
- 剪影训练集由404(加镜像)二进制剪影图像(白色前景和黑白背景)组成。那些二进制剪影图像是通过手动分割INRIA个人数据库的正图像块的一个子集获得的。每个训练轮廓图像通过树从根节点到叶节点,用于识别最佳路径(对应于最大匹配分数)。使用贪心搜索算法通过选择每个节点处的局部最优分支来估计最优路径。这可以由更复杂的动态规划算法代替,但是我们发现贪婪搜索工作得很好,速度要快得多。每个节点的匹配分数被计算为当前节点的部分模板与观察到的轮廓之间的覆盖程度(即,与训练剪影一致的假设内的像素的比例)。对于所有训练轮廓重复此过程,并且针对每个轮廓估计最佳路径。然后,基于路径集合,基于发生频率针对每个节点估计分支概率分布(分支边缘的条件分布)。
- 给定已知的分支概率,从根到叶的任何树路径可以与三个概率值(分别为三个部分ht,ul和ll)相关联。每个树节点现在携带部分模板的二进制图像,其边界采样点坐标和从树学习步骤获得的分支概率分布。由于路径和全局形状模型之间存在一一对应关系,因此每个全局形状模型现在由软覆盖图表示。我们累积所有路径的软覆盖图,以计算学习树的平均全局形状。图3通过显示学习的平均全局形状与所有训练轮廓的平均值非常相似,验证了我们的树学习方法。
- 补充:“我们累积所有路径的软覆盖图,以计算学习树的平均全局形状”,这句话的理解,每条路径都携带自身的概率,树的平均全局形状由所有路径乘以自身概率的和所得。
2.3 Hierarchical Part-Template Matching(分层部分模板匹配)
- 给定一个测试图像,我们使用扫描窗口方法来估计每个候选检测窗口的最佳姿势。对于每个窗口,我们将所学习的树与图像观察(边缘或边缘方向)相匹配,以估计路径节点的最佳树路径和相关位置参数。与用于树木学习的模型类似,特定检测的总体匹配得分窗口被简单地建模为沿着该路径的所有节点的匹配分数的总和。但是,与学习不同,测试阶段的匹配是在边缘或梯度取向而不是轮廓上执行的,并且每个节点的得分都被计算为部分模板匹配分数与该节点之前学习的先前可抢占性的乘积培训阶段。我们定性验证,结合分支先验概率给予姿态估计更好的鲁棒性。另一个区别是,在测试阶段,我们允许零件模板位置在本地移动,并且对于每个零件模板估计最佳位置,而不是固定零件模板位置。其中每个部分可以调整到其局部最佳位置。
- 我们使用类似于Chamfer匹配的方法匹配单个零件模板并计算零件模板匹配分数[6]。通过边缘方向匹配来测量零件模板轮廓上的采样点的匹配分数。目标是估计与图像观察最一致的最佳人类姿势(对应于路径上的每个部分模板的树路径和位置估计)。
- 优化问题可以通过动态规划解决,实现全局最优解。但是,这个算法在计算上太昂贵,不能密集地扫描所有的假想窗口。为了提高效率,我们使用快速的K-fold贪心搜索算法。我们保留层L1中所有节点(k = 1; 2。.K)的分数,而不是估计最佳k,并且对于这些K个节点(或线程)中的每一个单独执行贪婪过程。通过分层部分模板匹配算法估计的姿态模型参数直接用于通过部分合成(区域连接)进行姿态分割。
3 POSE-ADAPTIVE DESCRIPTORS(自适应描述)
- 为了将我们的部分模板树模型和分层部分模板匹配算法应用于区分人类检测,引入标准机器学习技术SVM和Boosting,并且介绍姿势自适应特征计算方法来从图像中检测人体。
3.2 Low-Level Feature Representation(低级特征表示)
- 在行人检测方面,定向梯度直方图(HOG)方法将人与非人分离表现出优异的性能,能忽略空间本身的信息,具有很强的鲁棒性。我们使用相似的方法—边缘方向直方图(梯度幅度加权)作为我们的低级特征描述。
- 输入图像,使用差分运算计算梯度G和边缘方向O,每幅图像量化为8*8的无重叠单元格。,用边缘取向直方图表示(每个周围的像素对直方图栏进行梯度变化的投票)。边缘方向被量化为Nb = 9,为了减少混叠和不连续性的影响,我们还使用三线插值法来计算空间和取向尺寸的梯度大小。
- 低级特征描述由一组原始直方图和一组归一化图像位置索引快组成。原始直方图携带梯度幅度信息,因此它们用于姿态匹配(匹配直方图对于树中姿势轮廓的边缘方向),而归一化直方图基于估计姿态用于最终描述符。
3.3 Pose Inference on the Low-Level Features(低级特征姿势推理)
- 通过方向一致性而不是传统倒角匹配中边缘之间的距离来测量得分。 使用基于位置的查找表来测量每个模板点的得分。 加权来自相邻直方图栏的幅度以减少定向偏差并使每个模板点的匹配分数正规化。
- 令O(t)轮廓点t处的边缘方向,与其对应的方向索引B(t)=[O(t)/(#/9)],#:圆周率。对于每个点t,我们首先在检测窗口中识别与之最邻近的8*8单元格。令H = (hi)表示t处的直方图,则t处的匹配分数计算为:
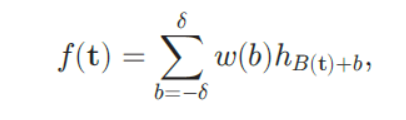 (1)
(1)
- 其中b表示领域范围,w(b)表示对称权重分布。如果给定一个模板T(部分模板上的边界采样点的集合),则该模板的匹配分数可以计算为:
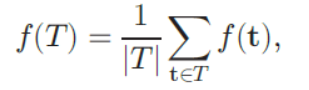 (2)
(2)
3.4 Representation Using Pose-Adaptive Descriptors(使用姿态自适应描述符表示)
- 为了获得具有不同尺寸姿态模型的图像的统一(恒定尺寸)描述,并且在不同的轮廓点之间建立一对一的对应关系姿势,我们将任何姿态模型的边界点映射到规范姿态模型的边界点。对于人体上部(头部和躯干),边界被均匀地取样为八个左侧和八个右侧位置,并且根据垂直y坐标和侧面(左侧或右侧)信息在姿势之间建立点对应关系。对于下体(腿),边界被均匀地采样到每个y值处具有四个位置的垂直,如何分配采样位置参照下图:
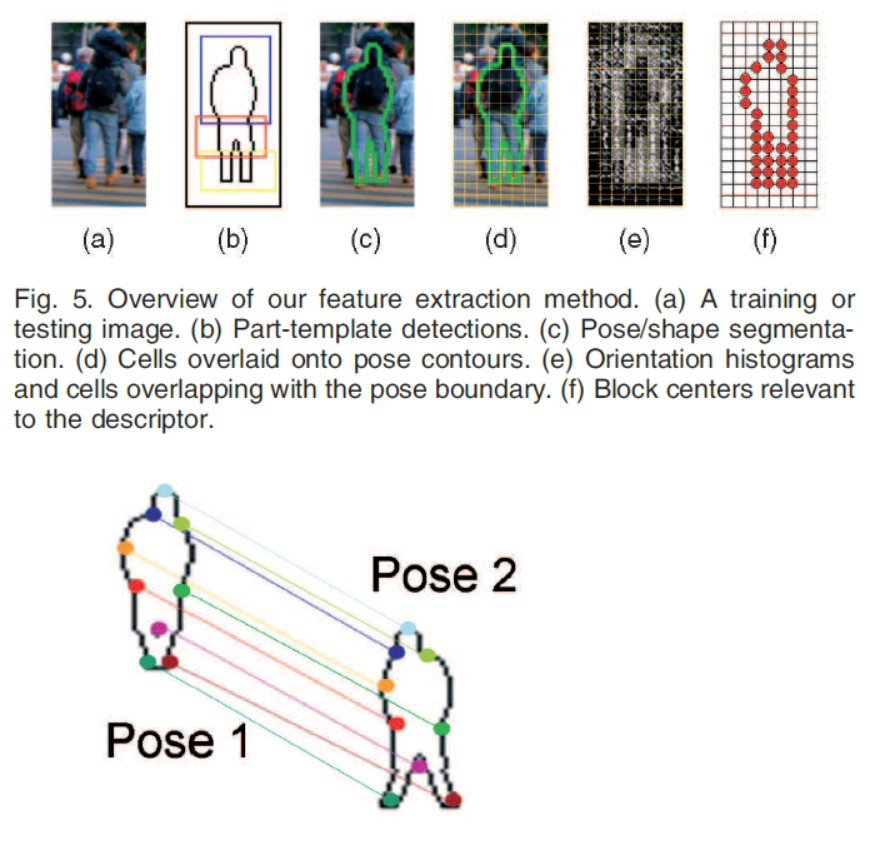
- 注意,只有块的子集与描述符相关,并且块可能会根据位于块内的轮廓点的频率重复多次。
4. DETECTING AND SEGMENTING MULTIPLE OCCLUDED HUMANS(检测和分类多个被检测的人)
- 上一节讨论的姿态自适应描述符主要是为了从图像中检测完全可视的人的目的而开发的。在这些复杂情况下,我们基于姿态自适应特征的通用检测器可用于提供初始 一组人类假设(通过降低阈值以确保低错失率),然后可以执行更详细的闭塞分析和优化。
4.1 Initial Hypotheses(初始假设)
- 使用我们的姿势适应特征训练的通用人体检测器和诸如SVM的辨别分类器可以提供用于从静止图像中检测人类的可靠的初始人类假设集合。 然而,对于拥挤的视频,由于人体的任何部分都可以闭塞,有时只能看到很小的一部分。 因此,在这里,我们介绍了一种替代方法,用于生成监控场景的初始人为假设。
- 分层部分模板匹配提供每个检测窗口的姿态模型参数的估计。 我们定义能够评估任何部分或部分组合的图像响应的分数函数Fw,该函数被建模为单个部分匹配分数fj的加权和:
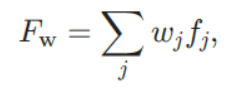 (3)
(3)
- 其中权重分布w={wj,j=ht,ul,ll}(三个wj之和等于1),若Wht = Wul = Wll = 1/3,则对应全是检测器。若Wht = 0,Wul = Wll = 1/2,则对应腿部检测器。对于得分函数Fw通过应用检测阈值,我们得到7个部分或分布组合检测器。如下图所示:
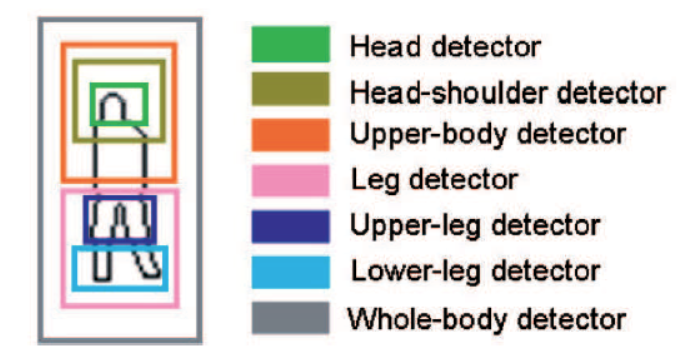
- 使用M部分检测器,对应于M个权重向量基于公式(2)计算单个零件匹配得分fi。
- 在实践中,我们从输入图像中构建一个金字塔,并使用我们的基于滑动窗口的通用人类检测器将搜索空间减少到一个小的子集,并通过使用上述部分/部分组合检测器搜索其他假设来提高搜索空间。每个响应图我们使用恒定的全局检测阈值,并自适应选择模式。 也可以在平滑似然图像之后通过局部最大选择来执行该步骤。 最大值的联合形成了人类假设的集合:
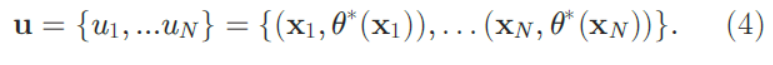
- 我们计算所有假设的全身匹配分数,并用L(ui),i,2…N表示。更具体点,L(ui)被计算为所有 部分模板轮廓点的平均匹配分数。
4.2 Objective Function(目标函数)
- 使用初始检测假设u作为图像观察,我们将多次闭塞人类检测模型作为最大化目标函数%的问题进行建模。
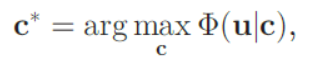
- 其中c表示有序的人体配置,n表示配置中的人数。
- 由于遮挡,不能直接用L(ui)来模拟%(u|c),相反,需要基于遮挡图Iocc全局重新估计每个假设ui的匹配分数。如果ui属于c,则仅基于或可见部分计算其匹配分数。我们通过从精确的人类分割生成的遮挡图在像素级处精确地执行遮挡补偿。这种基于遮挡补偿的评分重新评估方案在保留真实检测的同时有效地拒绝大多数假警报。
- 如果ui属于c,则存在j,使得ui = cj,并且因此,遮挡补偿匹配分数L(ui|Iocc)被定义为位于cj可见区域内的ui形状模板点的平均匹配分数;如果ui不属于c,则L(ui|Iocc)被设置为常数检测阈值α。基于上述建模,目标函数可以重写为:
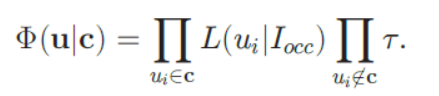
- 现在,给定任何有序的人类假设(配置),可以精确地评估目标函数。
5 COMBINING WITH CALIBRATION AND BACKGROUND SUBTRACTION(结合校准和背景技术)
- 我们还可以将基于形状的检测器与统一系统中的背景扣除和校准技术相结合。
问题
- 该论文介绍的是二维图像上人体的检测和分割,其中的方法如何应用到3维的医学图像分割上去?
- 论文树模型分块部分是先利用姿势生成其来产生人体的部分零件,然后再通过真实姿态图像学习来优化合成树模型,而并非一开始就是真实的人体图像,这一情况如何与医学图像的器官对应上?
- 分块程序对每一个脾脏和脑室分割时,每一块都是不规则的,而人体分块是规则的,是不是得寻找其他程序对器官分块,而分块的标准又是什么呢?