为什么要使用词嵌入(Word Embedding)
- 在词嵌入之前往往采用
1-of-N Encoding的方法,如下图所示:
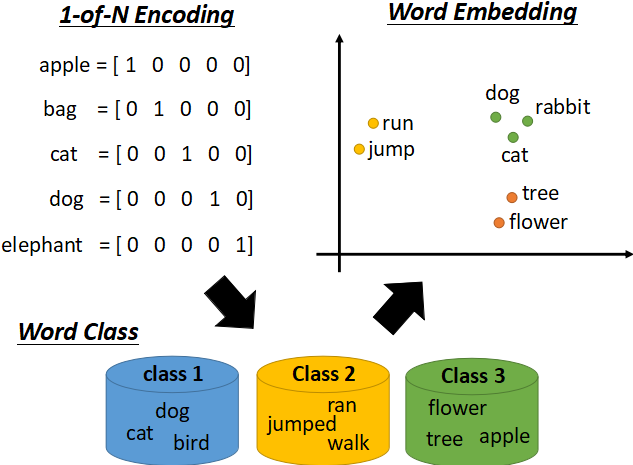
使用这种
1-of-N Encoding的方法有两种缺点:- 词向量是正交的,因为正交的属性不能体现出相似属性的词之间的关系。
- 这种方式编码的向量太长,若有10万个单词的话,就需要用长度为10万的向量进行编码,计算量和内存消耗都特别大。
为了克服以上缺点,我们引入
Word Embedding的方法。这种方法将词映射到高维之中(但是维数仍比 1-of-N Encoding 低很多),相似的词性的单词会聚集在一起,而不同词性 的单词会分开;每个坐标轴可以看作是区分这些单词的一种属性,比如说在上图中,横坐标可以认为是生物与其他的区别,纵坐标可以认为是会动和不会动的区别。因为在进行学习的过程中,我们只知道输入的是词的一种编码,输出的是词的另一种编码,但是并不知道具体应该是怎样的一种编码,**所以是
Word Embedding无监督学习。 **
词嵌入(Word Embedding)的两种方法
- 词嵌入(Word Embedding)主要有基于统计(Count based )和基于预测(Perdition based)的两种方法。
基于统计(Count based )的方法
- 基于统计的主要思想是:两词向量共同出现的频率比较高的话,那么这两个词向量也应该比较相似。如下图:

基于预测(Count based )的方法
- 在这里神经网络的输入是前一个单词 wi−1 的词向量(
1-of-N Encoding)形式,经过神将网络他的输出应该是下一个可能出现的单词 wi 是某一个词的几率,因为是1-of-N Encoding形式,所以输出的每一维代表是某一个词的概率。然后取第一层的权值输入 z 作为词向量。如下图:
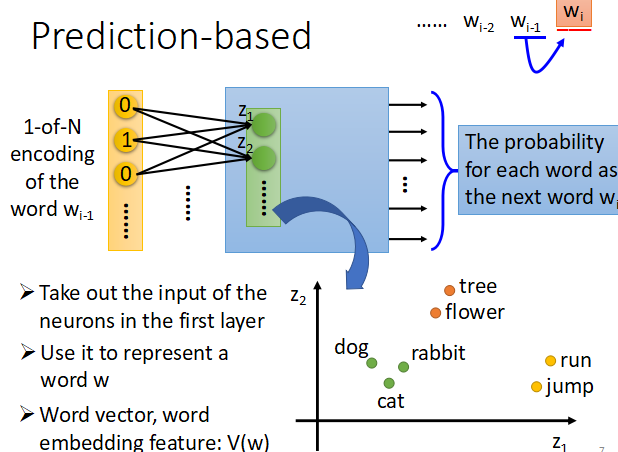
- 在实际使用中,往往找的不仅仅是一个词与下一个词之间的关系,而是通过前面一堆词推出后面的一个词,在训练的过程中有类似于权值共享的行为,如下图所示:
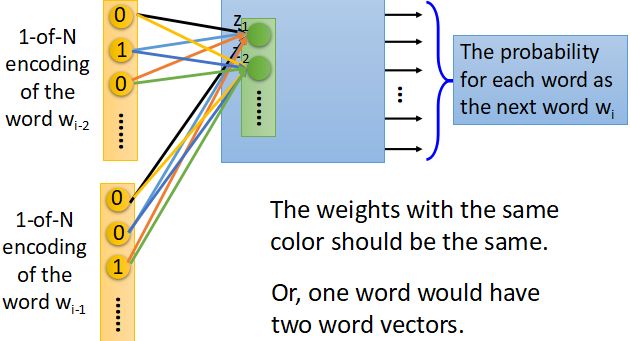
其中我们可以看到位于相同位置的输入神经元有着相同的权值(在途中用相同颜色的线表示出来),这样做的原因主要保证两点,首先在要保证对于在同一批输入的同一个位置的单词具有同样的编码(即相同的权重);
其次权值共享可以减少模型中参数的个数。
那么如何保证在训练的过程中它们具有相同的权重呢?如下图所示:
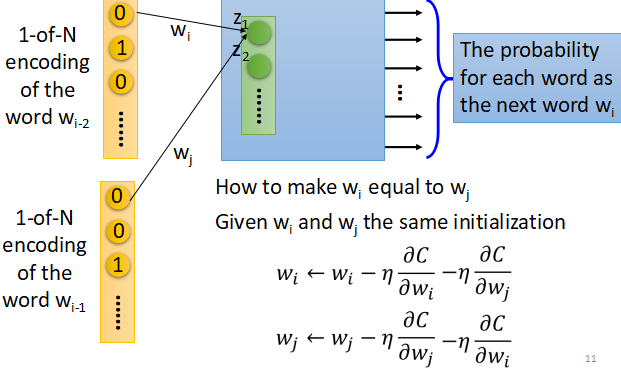
在梯度更新的过程中,首先对共享的权值参数设置相同的初始值,其次在更新的过程中不仅仅要减去自己对应的梯度,还应该减去另一个相同位置神经元的梯度,保证两个参数之间的更新过程是相同的。
除了可以根据之前的词推出后面的词,还可以根据两边的词推出中间的词,或者从中间的词推出两边的词,如图:
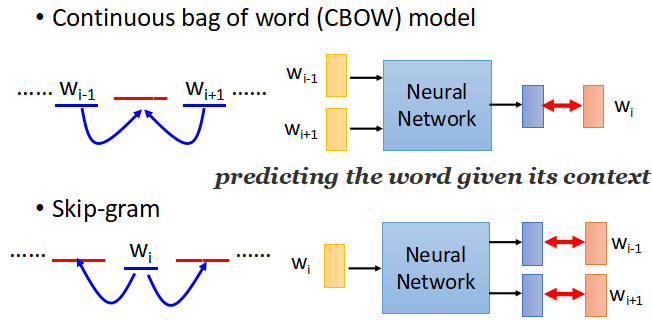
- 在这里虽然用了神经网络,但是并没有用deep learning,而只是用了一层的 linear hidden layer,主要是因为过去虽然有用过deep的方法,但是很难训练,并且实际上用一层就可以达到的效果。