
什么是生成模型
什么是生成(generation)?就是模型通过学习一些数据,然后生成类似的数据。让机器看一些动物图片,然后自己来产生动物的图片,这就是生成。
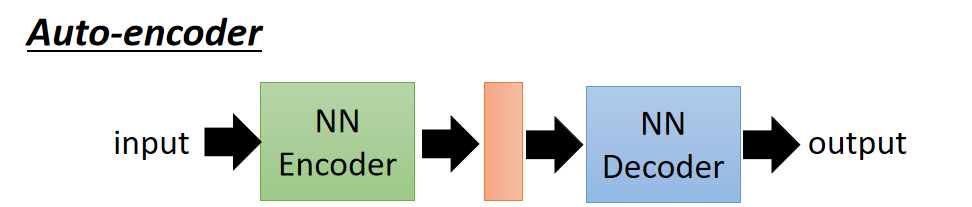
以前就有很多可以用来生成的技术了,比如auto-encoder(自编码器),你训练一个encoder,把input转换成code,然后训练一个decoder,把code转换成一个image,然后计算得到的image和input之间的MSE(mean square error),训练完这个model之后,取出后半部分NN Decoder,输入一个随机的code,就能generate一个image。
生成模型主要分为以下三种:
- PixelRNN;
- Variational Autoencoder(VAE)
- Generative Adversarial Network(GAN)
PixelRNN
- PixelRNN方法的主要过程如下图所示:
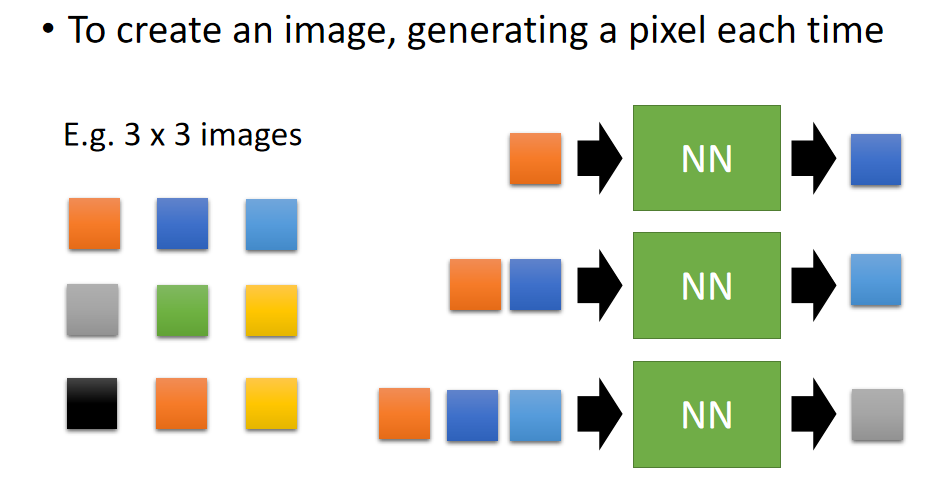
- 在训练的过程中,首先输入图像的第一个像素,这个时候网络输出的是图像的第二个像素,然后将第一第二个像素作为第二次伸进网络的输出,输出为第三个像素点,以此类推,对网络进行训练。
- 根据这个原理,我们可以输入半幅图像,通过该网络预测另外一半的样子。
- 假设我们给出了图像的一半,如下图,最左侧是原始图像,中间为输入遮挡一般的图像,希望补全另一半图像。后面是得到的三种结果。

- 在训练上面这个网络的时候,一个直观的方法是将图像的 RGB 三个通道作为输入,但是这种方法得到的测试结果往往会偏灰色和棕色,这是因为神经网络的输出常常使得输出的三个值在数值上十分接近。因此在这里利用 1 of N encoding 对颜色进行编码,但是如果对所有颜色进行编码的话,总共有256256256种编码,维数过高,所以首先对颜色进行聚类,对聚在一类的颜色使用相同的编码,大大降低了编码的维数。
Variational Autoencoder(VAE)
- Autoencoder在之前的博客无监督学习:深度自编码器中已经介绍了,主要过程如下所示:
- 如果随机产生 code 然后经过 decode 之后是可以产生图像,但是要产生需要的图像,这个时候就需要VAE的帮助了。VAE的主要过程如下图所示
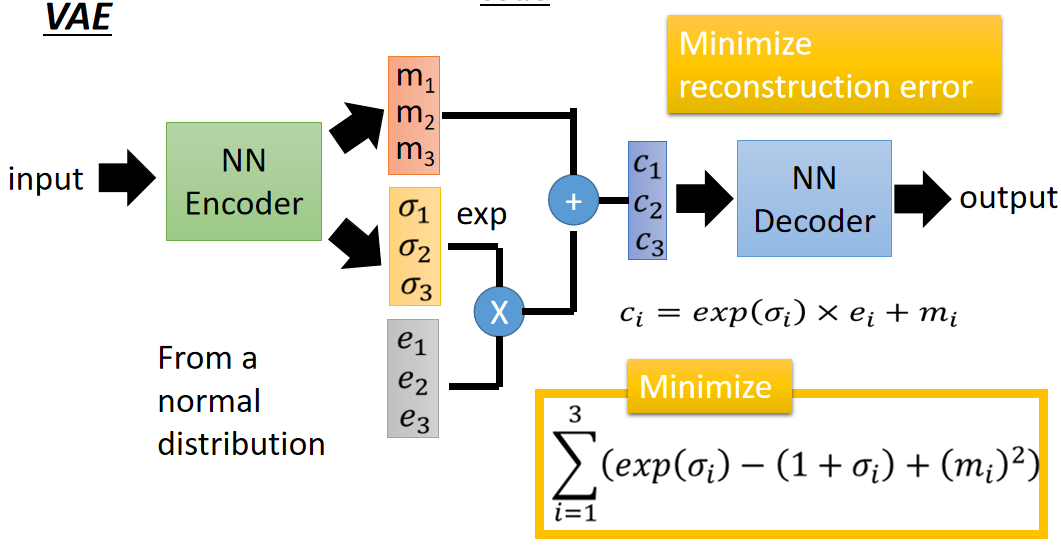
- 它的过程与 Aotuencoder 十分相似,前面的编码和后面的解码部分没有变化,中间的部分是添加的部分。首先如果你中间的编码部分希望得到的维数是3维的话,那么就会输出一个三维的 m 和一个三维的 σ,同时利用正态分布生成一个相同维数的向量 e ,经过计算得到编码 c(计算过程如上图所示),然后是解码的过程,最终的损失函数是同时最小化重建误差和下面的累加求和。
- 下面是VAE的实验结果:

- 可以看出来 VAE 想画点什么东西出来,但是并不知道 VAE 具体想画什么出来。
- 那么他与pixel Rnn 的区别在于哪呢?在 VAE 中,可以如下图所示
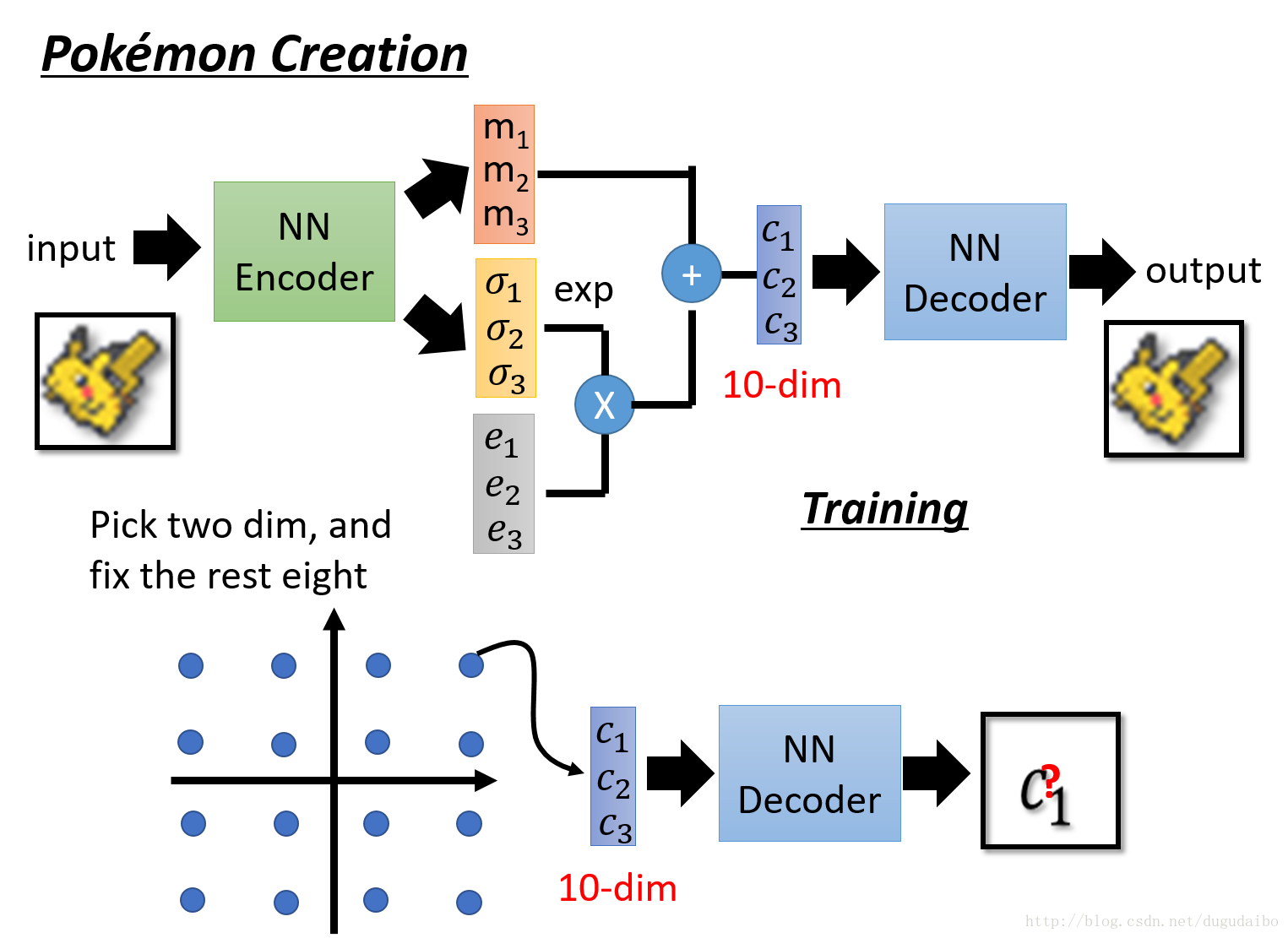
- 假如我们中间编码的是一个十维的向量,那么可以保持其中的八维不变,变化其中的两维,看看这两维对于图像的影响是怎样的。具体的实验结果如下图所示:

为什么要用VAE的直观解释
- 从直观的理解为什么使用VAE,与之前的自编码的区别在于哪里呢?
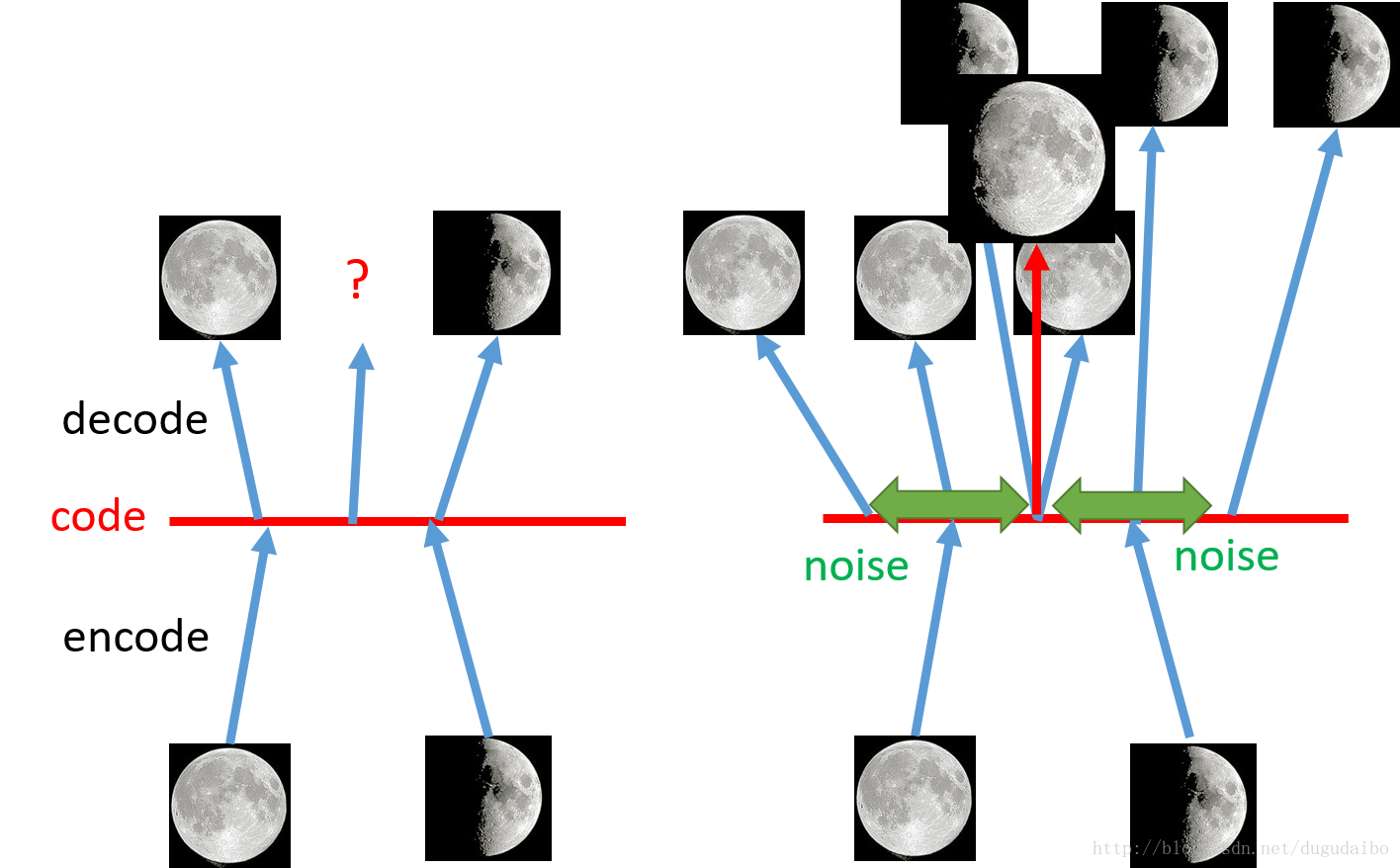
- 如上图,左侧是自编码过程,右侧是VAE过程。如果在左图中,取满月和弦月编码的之间点,输出的结果是怎么样的,会不会是介于两者之间的月相是不好说的。但是如果采用VAE的方法,他实际上相当于在编码的时候向里面加入了噪声,使得含有噪声的图像仍然可以恢复为原来的图像,那么加入取两者中间重叠的点,这个时候由于损失函数要使得恢复的误差最小,这样就需要综合满月和弦月的图像,很有可能就得到介于两者之间的图像。
- 加入噪声的原理如下图所示
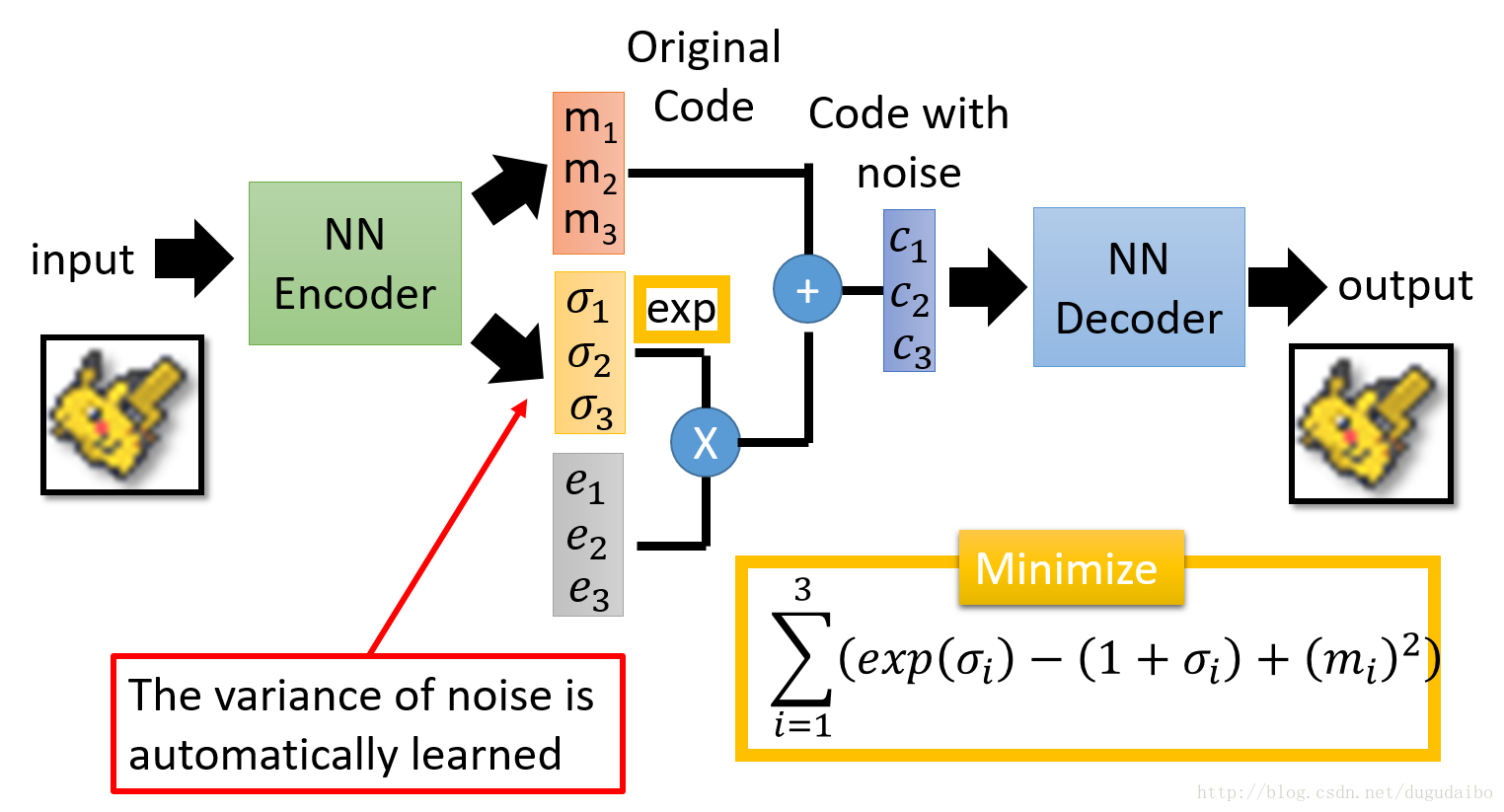
- 其中的 m 可以认为是原始的编码,而 σ 认为是方差,e 本身是从正太分布得到的,所以本身有固定的方差,将两者相乘相当于向编码中加入方差为某一个值的噪声,其中e 要取指数,这个时候就可以保证所得到的方差是整数的,而且又由于 σ 是通过网络得到的,所以网络在学习中可以自动调节噪声方差的大小。
- 在训练这个网络时,不仅仅只是用之前的重建误差最小,还需要加入如上图黄色框中的那一项最小。因为如果让网络自己随便学习的话,他会倾向于不在网络中加入噪声,如果这样的话他就与之前的自编码器没有区别了,所以需要加入如下图的惩罚项。
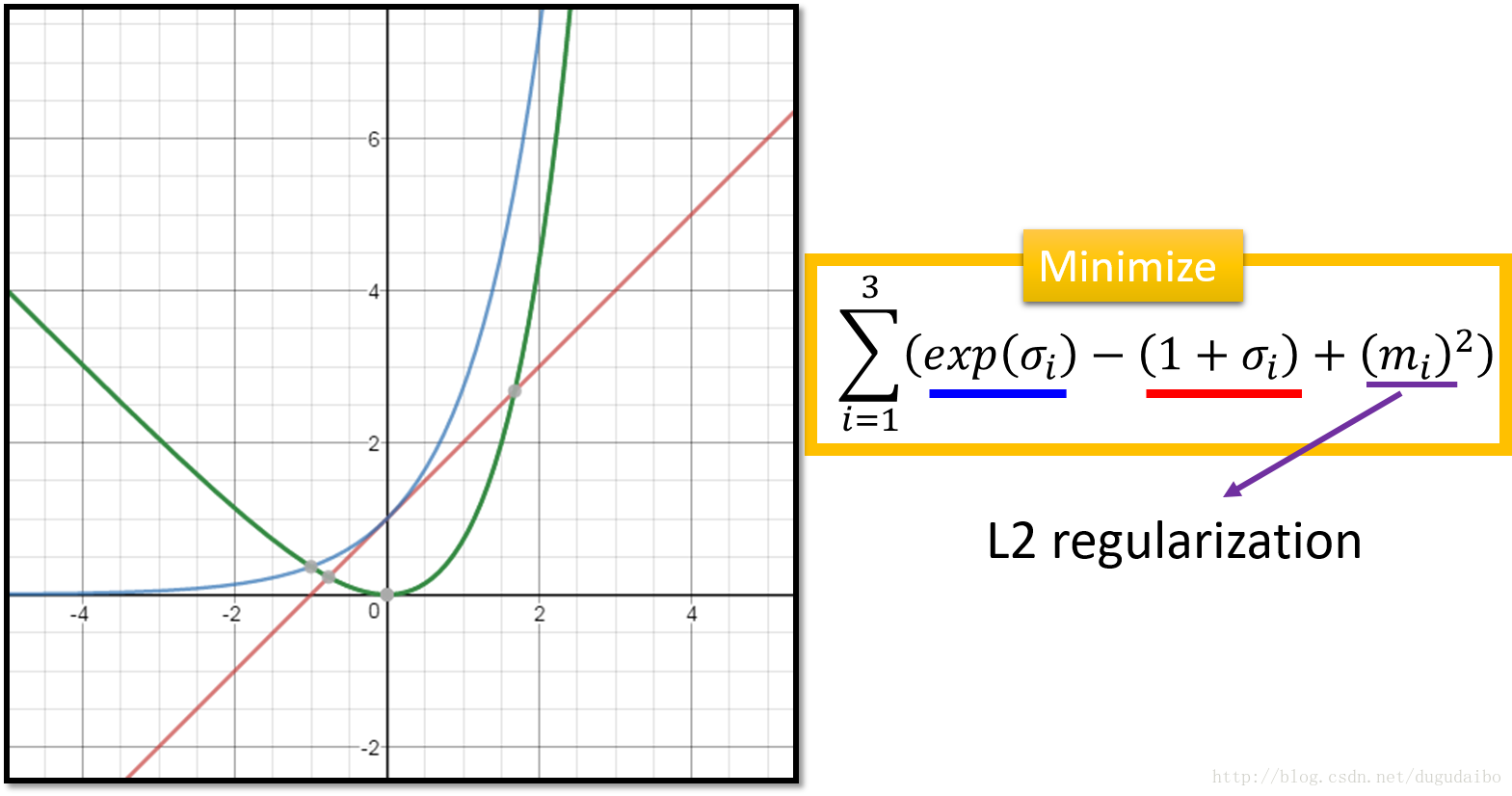
- 其中蓝色的那一项如图中的蓝色的曲线所示,途中红色的项如图中红色的曲线所示,两项相减得到的结果如图中的绿色曲线所示。我们可以看到,如果要使这一项取到最小值需要使得 σi 的值为0,这个时候 exp(σi)的值为1,而不是零,这样就可以保证加入模型中的方差不是0,即有噪声加入网络中。其中的 m 直接认为是正则项就好,可以增强模型鲁棒性。
从VAE的原理解释为什使用VAE
- 回到问题的本身,我们实际上是希望生成图像。假如我们将图像看作是高维空间上的一个点,那么我们需要的就是估计这些点在高维空间的分布,这个概率分布的大概的形式应该如下图所示:

- 它在有宝可梦存在的地方的概率应该比较高,在没有宝可梦的区域应该比较低。所以可以从概率比较高的部分进行抽样,生成新的数据。
- 而估计概率这件事情可以使用高斯混合模型。高斯混合模型可以大概表示为下图的样子
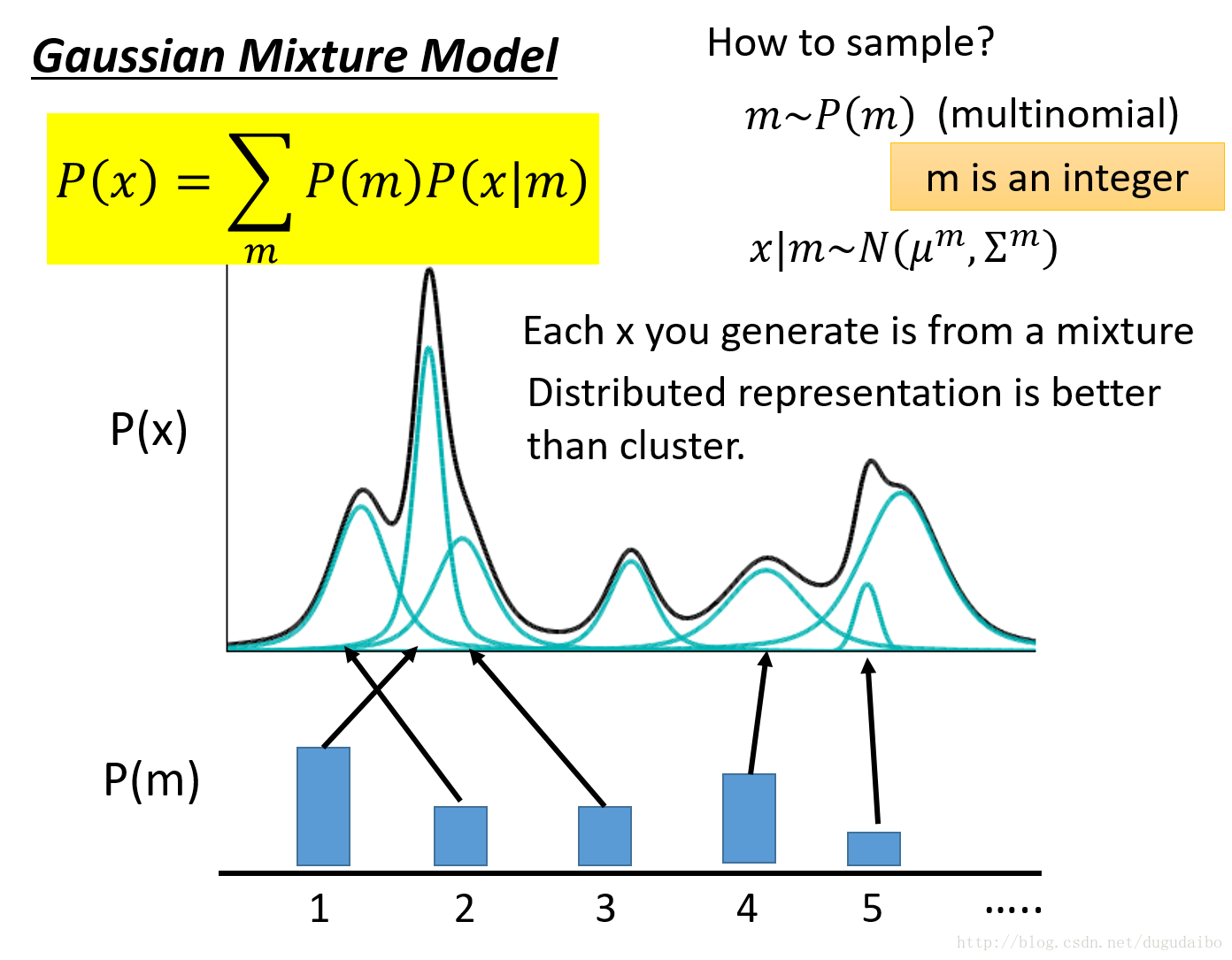
- 其中黑线是高斯混合模型的概率密度曲线,它是由许许多多个高斯模型按照一定的权重混合得到的。那如何从这样的混合模型中进行采样呢?首先我们选取从组成高斯混合模型的若干个高斯分布中选择使用哪一个高斯分布,然后对于选定的某一个高斯分布,他有着自己的均值和方差 μm,Σm ,根据他的均值和方差,就可以从中采样。
- 对于高斯混合模型中参数的估计,实际上可以利用数据通过EM算法进行估计。
- 实际上,之前有讲过,对数据进行聚类的话,不如对数据进行分布式的表示,有多少的概率属于A,有多少的概率属于B等等……而本质上,VAE就是高斯混合模型的分布表示的形式。
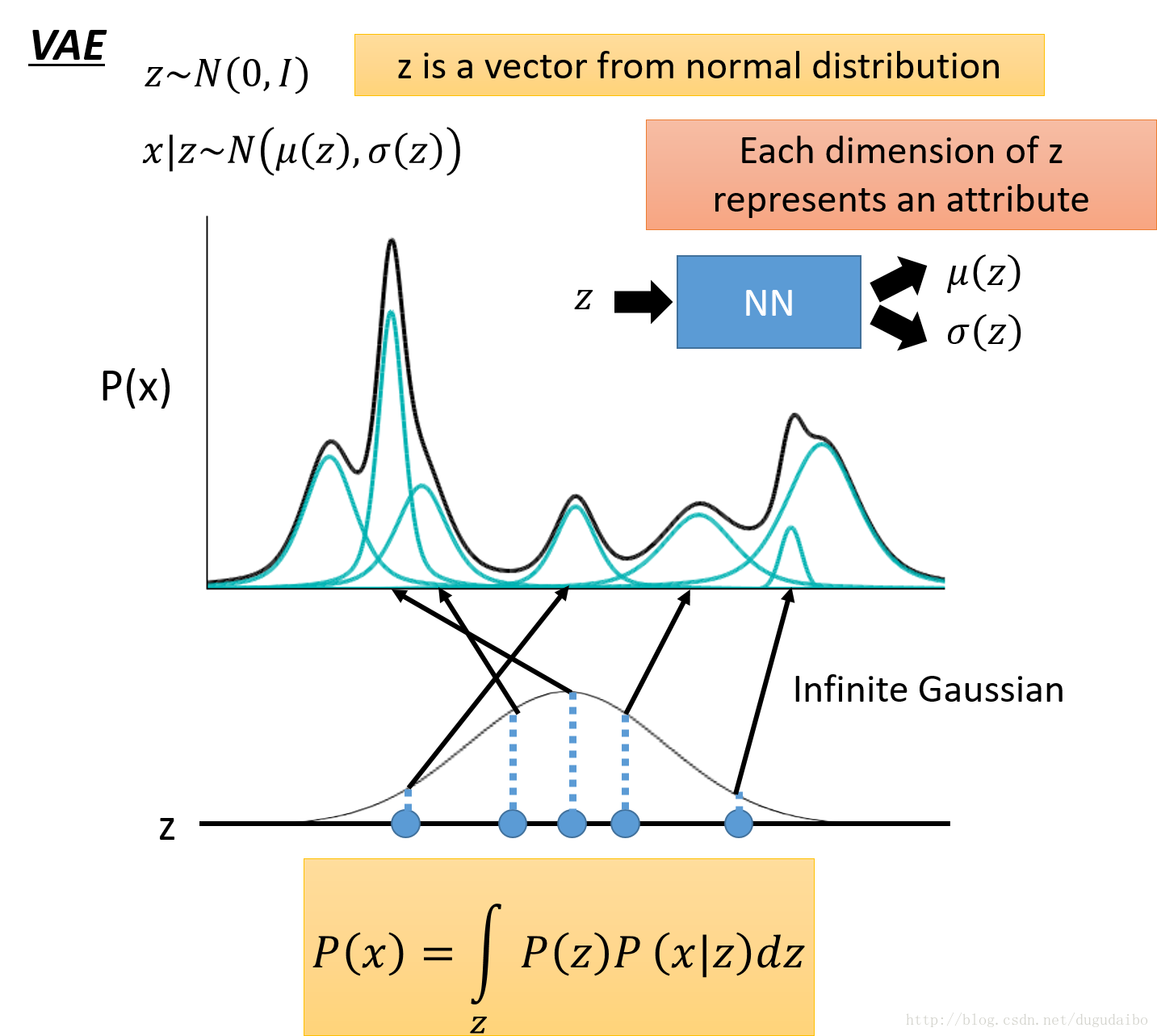
- 假设 z 服从某一个标准概率分布,从这样的分布中采样若干个点,其中 z 可能是一个多维的向量,每一个维度代表一个属性。以一个 1 维的高斯分布为例,我们从中采样出一个 z ,然后根据 z 决定所对应的高斯分布的均值和方差 μ(z),σ(z) ,在这里我们的 z 有无穷种可能,不想之前的混合模型中只是几种高斯模型的混合。所以现在给定了某一个 z 那么如何得到对应的均值和方差呢?这里我们假设均值和方差是通过一个函数得到的,就是说给定一个输入 z 就会得到一个均值和方差(实际上就是一个高斯分布)。所以可以认为它们是通过一个神经网络的均值和方差(也就是说输入一个 z 输出可一个对应的高斯分布)。所以 P(x) 的表示方式就如上图所示。
- 在下面的这个用来采样的分布不一定非要是一个标准的高斯分布,可以是任何分布。因为NN是powerful 的,它可以通过神经网络得到。
VAE存在的问题
- VAE主要的问题在于,他一直希望能够模仿已经存在的数字,而不是希望真正的生成一张图像,如下图所示:
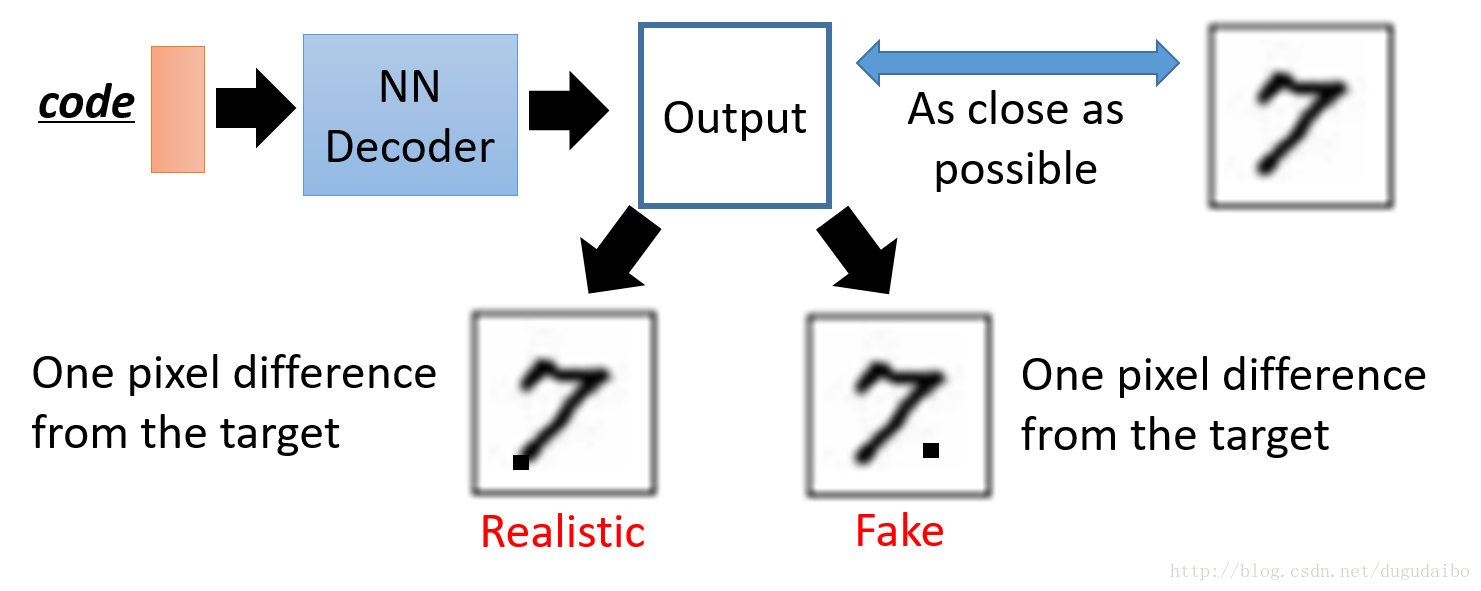
- 假设生成的图像与原始的图像只有一个像素的差距,这个像素的位置有如图中的两种可能,可以明显看出左侧的那个图是更现实的,而右侧的图明显比较假,但是对于VAE来说这两张图象之间的loss很有可能是一样的,所以才会导致这样的问题。为了解决这个问题,才有后文的 GAN 模型。
生成对抗网络(GAN)
- 大名鼎鼎的GAN是如何生成图片的呢?首先大家都知道GAN有两个网络,一个是generator,一个是discriminator,通过两个网络互相对抗来达到最好的生成效果。流程如下:
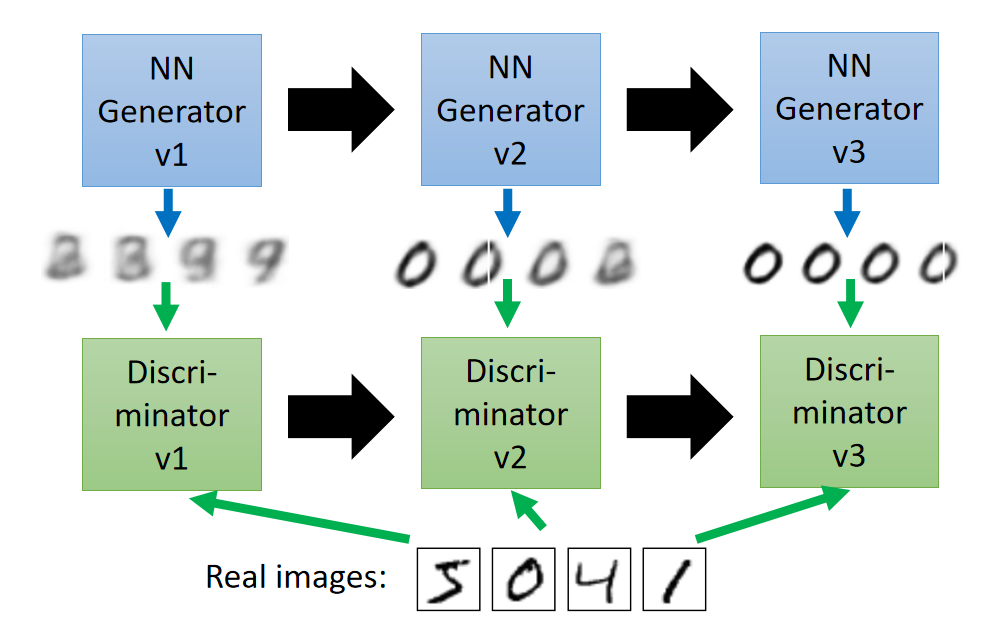
- 主要流程类似上面这个图。首先,有一个一代的generator,它能生成一些很差的图片,然后有一个一代的discriminator,它能准确的把生成的图片,和真实的图片分类,简而言之,这个discriminator就是一个二分类器,对生成的图片输出0,对真实的图片输出1。
- 接着,开始训练出二代的generator,它能生成稍好一点的图片,能够让一代的discriminator认为这些生成的图片是真实的图片。然后会训练出一个二代的discriminator,它能准确的识别出真实的图片,和二代generator生成的图片。以此类推,会有三代,四代。。。n代的generator和discriminator,最后discriminator无法分辨生成的图片和真实图片,这个网络就拟合了。