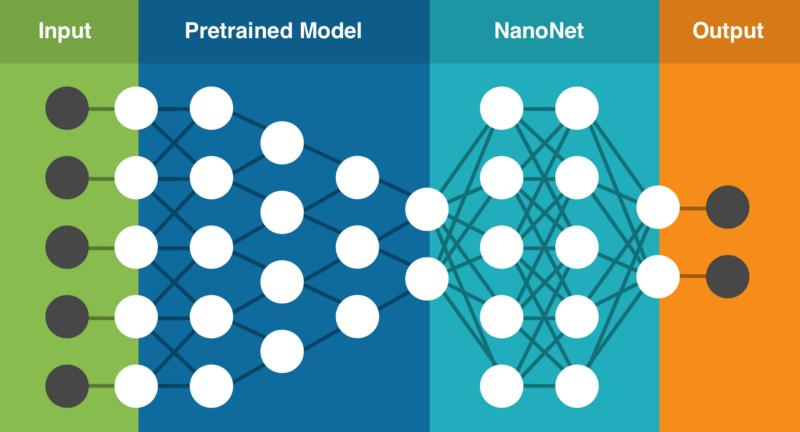
什么是迁移学习?
- 通常对于同一类型的事业,我们不用自己完全从头做, 可以借鉴别人的经验, 往往能节省很多时间. 有这样的思路, 机器学习也能偷偷懒, 不用花时间重新训练一个无比庞大的神经网络, 借鉴借鉴一个已经训练好的神经网络就行.这就叫迁移学习。
- 比如这样的一个神经网络, 我花了两天训练完之后, 它已经能正确区分图片中具体描述的是男人, 女人还是眼镜. 说明这个神经网络已经具备对图片信息一定的理解能力. 这些理解能力就以参数的形式存放在每一个神经节点中. 不巧, 领导下达了一个紧急任务,要求今天之内训练出来一个预测图片里实物价值的模型. 我想这可完蛋了, 上一个图片模型都要花两天, 如果要再搭个模型重新训练, 今天肯定出不来呀. 这时, 迁移学习来拯救我了.
- 因为这个训练好的模型中已经有了一些对图片的理解能力, 而模型最后输出层的作用是分类之前的图片, 对于现在计算价值的任务是用不到的, 所以我将最后一层替换掉, 变为服务于现在这个任务的输出层. #接着只训练新加的输出层, 让理解力保持始终不变. 前面的神经层庞大的参数不用再训练, 节省了我很多时间, 我也在一天时间内, 将这个任务顺利完成。
如何做迁移学习?
在实践中,我们通常不会完全从头开始随机初始化训练 DCNN,这是因为有能满足深度网络需求的足够大小的数据集相当的少见。作为代替,常见的是在一个大型数据集上预训练一个 DCNN,然后使用这一训练的 DCNN 的权重作为初始设置或作为相关任务的固定的特征提取器。 举个例子,我们知道Imagnet是目前最大的图像识别数据库,目前已经有很多基于imagenet数据训练的网络模型,如inceptionv3、v4等,假如现在给你一个任务,希望你能做一个车系识别,你有两个选择:
- 一是搜集大量的车系数据,对这些车系数据进行模型训练;
- 二是基于imagenet训练好的网络模型,然后把搜集好的车系数据加到基于之前训练好的模型继续训练,进行fine-tuning(微调)。
传统的做法都是第一种,但是这就会遇到一个问题,一是车系的图片够不够多,体量够不够大?如果数据量不够,最后训练的效果会不会很不好?其实我们可以通过 把ImageNet 或其他大型数据集学习到的网络特征运用于一个图片分类或其他基于图片特征的任务,这就是迁移学习的思想。其实可以这样理解,如果从零开始训练,那么初始化权重一般情况下要么是都为0,要么随机设置,当我们导入了在大规模数据集上训练好的模型后,相当于在以这个模型现有的参数作为初始化的权重,不过至于在具体的任务上的泛化能力如何,还是得看具体的场景。
迁移学习为什么能work?
- 通常我们在做深度学习的时候,网络的每一个layer分别提取训练集上的不同特征,假如我们要用NN去做大象识别,可能第一层的NN的作用是判断图片上的动物是否有腿,第二层判断是否有尾巴….然后剩下的每一层都分别提取图片上的不同特征,当所有的特征都满足时则判断为大象,如果有特征不满足的话,则判断为不是大象,如下图所示:
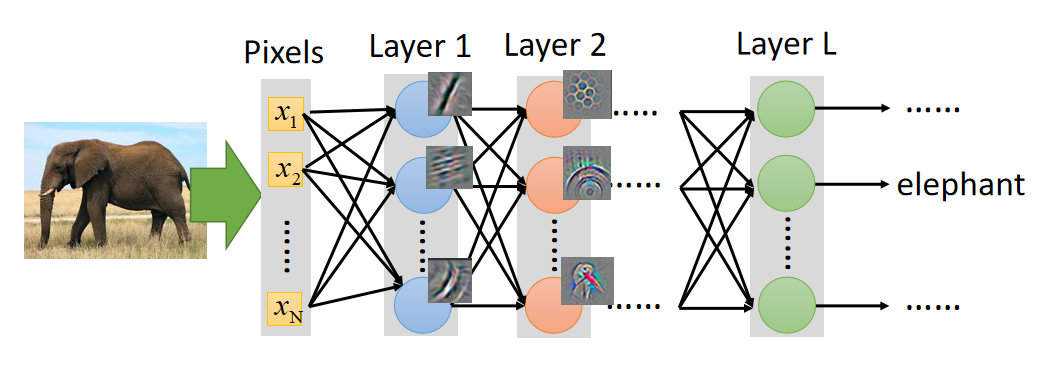
- 所以当我们要重新训练一个网络去识别其它动物的时候,例如识别猫与狗,我们就可以不用重新训练这个网络,可以把大象的那个NN前面几层拿过来,猫与狗他们有某些相同的特征,例如都有腿、都有尾巴、都有耳朵,因此我们把识别相同特征的layer直接拿过来用,相当于借鉴前人已有的经验,借鉴过来的网络不用训练,因为参数在之前已经训练好了,我们只需要训练新加的layer就好了,这样可以大量的节省网络训练的时间,而且就算我们的训练数据不足也能取得很好的性能。
迁移学习的限制
- 上文提到我们在迁移学习中会使用预训练的网络,所以我们在模型架构方面受到了一点点限制。比如说,我们不能随意移除预训练网络中的卷积层。但由于参数共享的关系,我们可以很轻松地在不同空间尺寸的图像上运行一个预训练网络。这在卷积层和池化层和情况下是显而易见的,因为它们的前向函数(forward function)独立于输入内容的空间尺寸。在全连接层(FC)的情形中,这仍然成立,因为全连接层可被转化成一个卷积层。所以当我们导入一个预训练的模型时,网络结构需要与预训练的网络结构相同,然后再针对特定的场景和任务进行训练。
迁移学习相关资料
- 对迁移学习感兴趣的同学,可以关注这个github repo:transferlearning,里面所有的资料与数据集都是由王晋东所整理。